[ad_1]
Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. Part of this commitment involves developing high-quality speech synthesis technologies, which build upon projects such as VDTTS and AudioLM, for users that speak many different languages.
 |
After developing a new model, one must evaluate whether the speech it generates is accurate and natural: the content must be relevant to the task, the pronunciation correct, the tone appropriate, and there should be no acoustic artifacts such as cracks or signal-correlated noise. Such evaluation is a major bottleneck in the development of multilingual speech systems.
The most popular method to evaluate the quality of speech synthesis models is human evaluation: a text-to-speech (TTS) engineer produces a few thousand utterances from the latest model, sends them for human evaluation, and receives results a few days later. This evaluation phase typically involves listening tests, during which dozens of annotators listen to the utterances one after the other to determine how natural they sound. While humans are still unbeaten at detecting whether a piece of text sounds natural, this process can be impractical — especially in the early stages of research projects, when engineers need rapid feedback to test and restrategize their approach. Human evaluation is expensive, time consuming, and may be limited by the availability of raters for the languages of interest.
Another barrier to progress is that different projects and institutions typically use various ratings, platforms and protocols, which makes apples-to-apples comparisons impossible. In this regard, speech synthesis technologies lag behind text generation, where researchers have long complemented human evaluation with automatic metrics such as BLEU or, more recently, BLEURT.
In “SQuId: Measuring Speech Naturalness in Many Languages“, to be presented at ICASSP 2023, we introduce SQuId (Speech Quality Identification), a 600M parameter regression model that describes to what extent a piece of speech sounds natural. SQuId is based on mSLAM (a pre-trained speech-text model developed by Google), fine-tuned on over a million quality ratings across 42 languages and tested in 65. We demonstrate how SQuId can be used to complement human ratings for evaluation of many languages. This is the largest published effort of this type to date.
Evaluating TTS with SQuId
The main hypothesis behind SQuId is that training a regression model on previously collected ratings can provide us with a low-cost method for assessing the quality of a TTS model. The model can therefore be a valuable addition to a TTS researcher’s evaluation toolbox, providing a near-instant, albeit less accurate alternative to human evaluation.
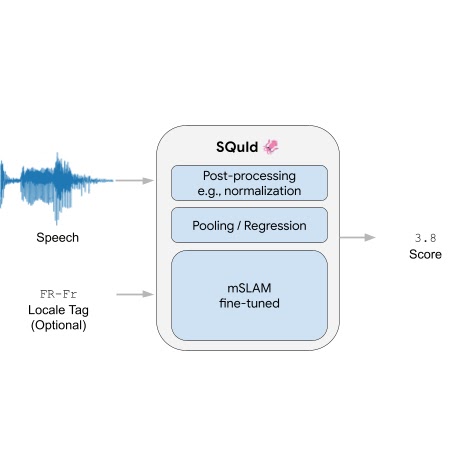
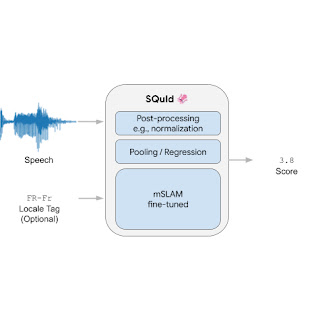
SQuId takes an utterance as input and an optional locale tag (i.e., a localized variant of a language, such as “Brazilian Portuguese” or “British English”). It returns a score between 1 and 5 that indicates how natural the waveform sounds, with a higher value indicating a more natural waveform.
Internally, the model includes three components: (1) an encoder, (2) a pooling / regression layer, and (3) a fully connected layer. First, the encoder takes a spectrogram as input and embeds it into a smaller 2D matrix that contains 3,200 vectors of size 1,024, where each vector encodes a time step. The pooling / regression layer aggregates the vectors, appends the locale tag, and feeds the result into a fully connected layer that returns a score. Finally, we apply application-specific post-processing that rescales or normalizes the score so it is within the [1, 5] range, which is common for naturalness human ratings. We train the whole model end-to-end with a regression loss.
The encoder is by far the largest and most important piece of the model. We used mSLAM, a pre-existing 600M-parameter Conformer pre-trained on both speech (51 languages) and text (101 languages).
 |
| The SQuId model. |
To train and evaluate the model, we created the SQuId corpus: a collection of 1.9 million rated utterances across 66 languages, collected for over 2,000 research and product TTS projects. The SQuId corpus covers a diverse array of systems, including concatenative and neural models, for a broad range of use cases, such as driving directions and virtual assistants. Manual inspection reveals that SQuId is exposed to a vast range of of TTS errors, such as acoustic artifacts (e.g., cracks and pops), incorrect prosody (e.g., questions without rising intonations in English), text normalization errors (e.g., verbalizing “7/7” as “seven divided by seven” rather than “July seventh”), or pronunciation mistakes (e.g., verbalizing “tough” as “toe”).
A common issue that arises when training multilingual systems is that the training data may not be uniformly available for all the languages of interest. SQuId was no exception. The following figure illustrates the size of the corpus for each locale. We see that the distribution is largely dominated by US English.
 |
| Locale distribution in the SQuId dataset. |
How can we provide good performance for all languages when there are such variations? Inspired by previous work on machine translation, as well as past work from the speech literature, we decided to train one model for all languages, rather than using separate models for each language. The hypothesis is that if the model is large enough, then cross-locale transfer can occur: the model’s accuracy on each locale improves as a result of jointly training on the others. As our experiments show, cross-locale proves to be a powerful driver of performance.
Experimental results
To understand SQuId’s overall performance, we compare it to a custom Big-SSL-MOS model (described in the paper), a competitive baseline inspired by MOS-SSL, a state-of-the-art TTS evaluation system. Big-SSL-MOS is based on w2v-BERT and was trained on the VoiceMOS’22 Challenge dataset, the most popular dataset at the time of evaluation. We experimented with several variants of the model, and found that SQuId is up to 50.0% more accurate.
 |
| SQuId versus state-of-the-art baselines. We measure agreement with human ratings using the Kendall Tau, where a higher value represents better accuracy. |
To understand the impact of cross-locale transfer, we run a series of ablation studies. We vary the amount of locales introduced in the training set and measure the effect on SQuId’s accuracy. In English, which is already over-represented in the dataset, the effect of adding locales is negligible.
 |
| SQuId’s performance on US English, using 1, 8, and 42 locales during fine-tuning. |
However, cross-locale transfer is much more effective for most other locales:
 |
| SQuId’s performance on four selected locales (Korean, French, Thai, and Tamil), using 1, 8, and 42 locales during fine-tuning. For each locale, we also provide the training set size. |
To push transfer to its limit, we held 24 locales out during training and used them for testing exclusively. Thus, we measure to what extent SQuId can deal with languages that it has never seen before. The plot below shows that although the effect is not uniform, cross-locale transfer works.
 |
| SQuId’s performance on four “zero-shot” locales; using 1, 8, and 42 locales during fine-tuning. |
When does cross-locale operate, and how? We present many more ablations in the paper, and show that while language similarity plays a role (e.g., training on Brazilian Portuguese helps European Portuguese) it is surprisingly far from being the only factor that matters.
Conclusion and future work
We introduce SQuId, a 600M parameter regression model that leverages the SQuId dataset and cross-locale learning to evaluate speech quality and describe how natural it sounds. We demonstrate that SQuId can complement human raters in the evaluation of many languages. Future work includes accuracy improvements, expanding the range of languages covered, and tackling new error types.
Acknowledgements
The author of this post is now part of Google DeepMind. Many thanks to all authors of the paper: Ankur Bapna, Joshua Camp, Diana Mackinnon, Ankur P. Parikh, and Jason Riesa.
[ad_2]
Source link