[ad_1]
Software isn’t created in one dramatic step. It improves bit by bit, one little step at a time — editing, running unit tests, fixing build errors, addressing code reviews, editing some more, appeasing linters, and fixing more errors — until finally it becomes good enough to merge into a code repository. Software engineering isn’t an isolated process, but a dialogue among human developers, code reviewers, bug reporters, software architects and tools, such as compilers, unit tests, linters and static analyzers.
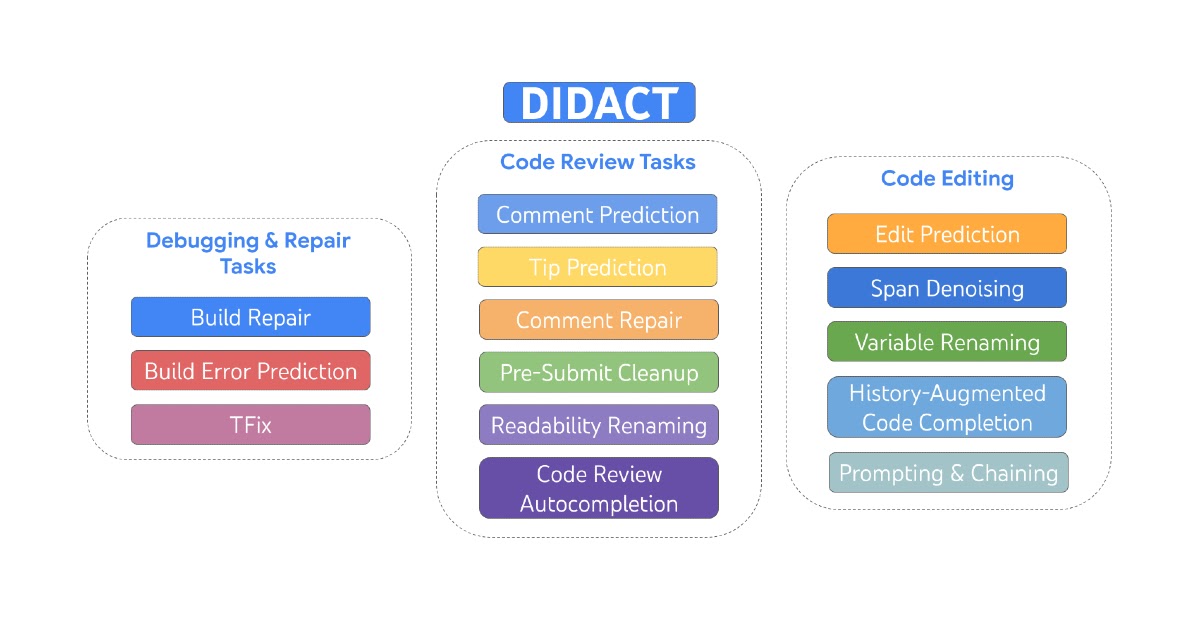
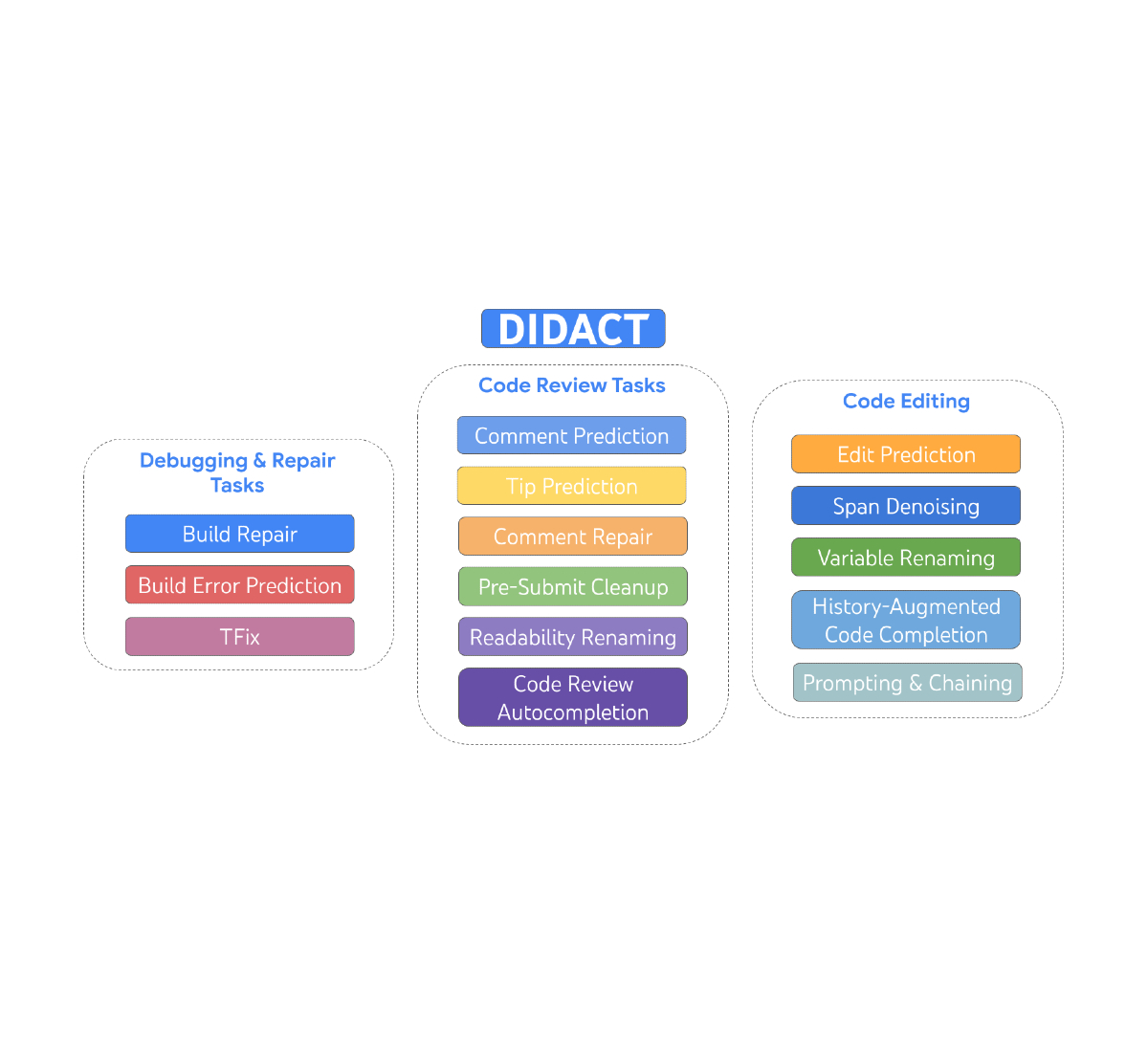
Today we describe DIDACT (Dynamic Integrated Developer ACTivity), which is a methodology for training large machine learning (ML) models for software development. The novelty of DIDACT is that it uses the process of software development as the source of training data for the model, rather than just the polished end state of that process, the finished code. By exposing the model to the contexts that developers see as they work, paired with the actions they take in response, the model learns about the dynamics of software development and is more aligned with how developers spend their time. We leverage instrumentation of Google’s software development to scale up the quantity and diversity of developer-activity data beyond previous works. Results are extremely promising along two dimensions: usefulness to professional software developers, and as a potential basis for imbuing ML models with general software development skills.
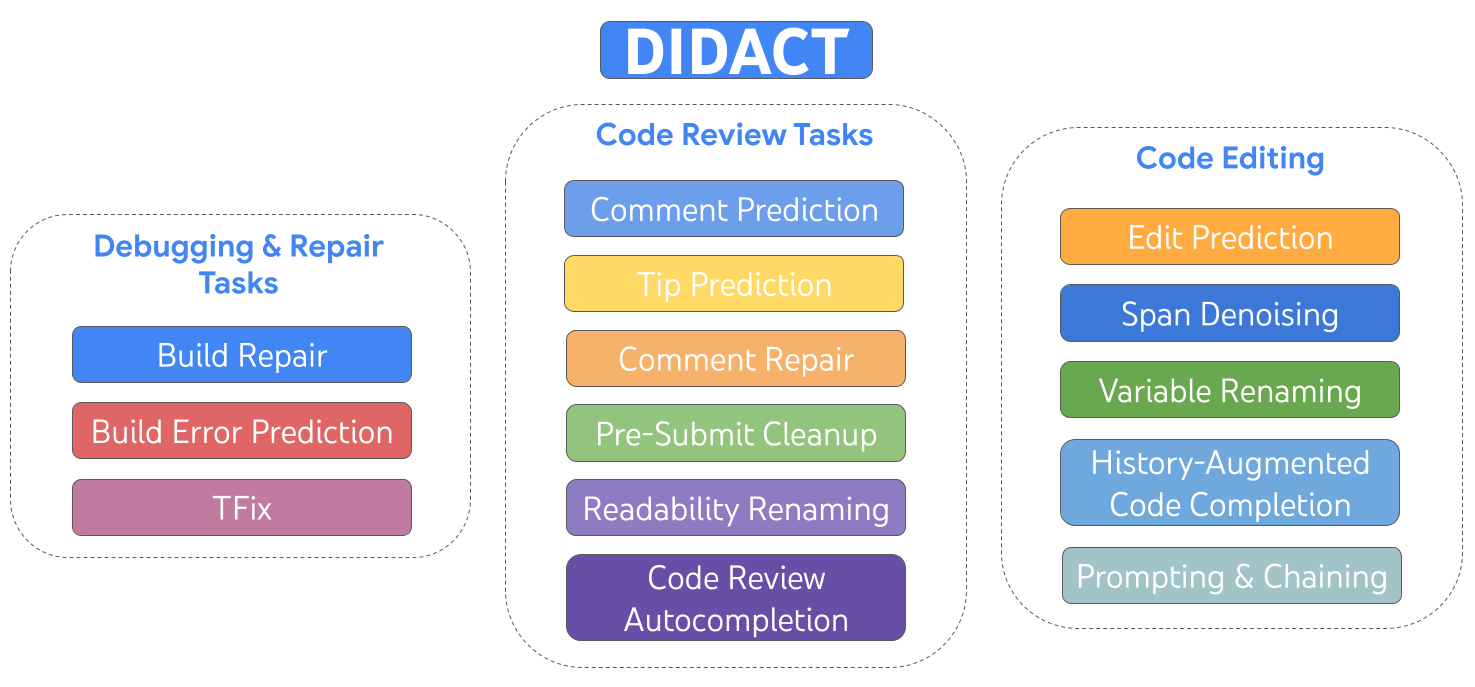 |
| DIDACT is a multi-task model trained on development activities that include editing, debugging, repair, and code review. |
We built and deployed internally three DIDACT tools, Comment Resolution (which we recently announced), Build Repair, and Tip Prediction, each integrated at different stages of the development workflow. All three of these tools received enthusiastic feedback from thousands of internal developers. We see this as the ultimate test of usefulness: do professional developers, who are often experts on the code base and who have carefully honed workflows, leverage the tools to improve their productivity?
Perhaps most excitingly, we demonstrate how DIDACT is a first step towards a general-purpose developer-assistance agent. We show that the trained model can be used in a variety of surprising ways, via prompting with prefixes of developer activities, and by chaining together multiple predictions to roll out longer activity trajectories. We believe DIDACT paves a promising path towards developing agents that can generally assist across the software development process.
A treasure trove of data about the software engineering process
Google’s software engineering toolchains store every operation related to code as a log of interactions among tools and developers, and have done so for decades. In principle, one could use this record to replay in detail the key episodes in the “software engineering video” of how Google’s codebase came to be, step-by-step — one code edit, compilation, comment, variable rename, etc., at a time.
Google code lives in a monorepo, a single repository of code for all tools and systems. A software developer typically experiments with code changes in a local copy-on-write workspace managed by a system called Clients in the Cloud (CitC). When the developer is ready to package a set of code changes together for a specific purpose (e.g., fixing a bug), they create a changelist (CL) in Critique, Google’s code-review system. As with other types of code-review systems, the developer engages in a dialog with a peer reviewer about functionality and style. The developer edits their CL to address reviewer comments as the dialog progresses. Eventually, the reviewer declares “LGTM!” (“looks good to me”), and the CL is merged into the code repository.
Of course, in addition to a dialog with the code reviewer, the developer also maintains a “dialog” of sorts with a plethora of other software engineering tools, such as the compiler, the testing framework, linters, static analyzers, fuzzers, etc.
 |
| An illustration of the intricate web of activities involved in developing software: small actions by the developer, interactions with a code reviewer, and invocations of tools such as compilers. |
A multi-task model for software engineering
DIDACT utilizes interactions among engineers and tools to power ML models that assist Google developers, by suggesting or enhancing actions developers take — in context — while pursuing their software-engineering tasks. To do that, we have defined a number of tasks about individual developer activities: repairing a broken build, predicting a code-review comment, addressing a code-review comment, renaming a variable, editing a file, etc. We use a common formalism for each activity: it takes some State (a code file), some Intent (annotations specific to the activity, such as code-review comments or compiler errors), and produces an Action (the operation taken to address the task). This Action is like a mini programming language, and can be extended for newly added activities. It covers things like editing, adding comments, renaming variables, marking up code with errors, etc. We call this language DevScript.
 |
| The DIDACT model is prompted with a task, code snippets, and annotations related to that task, and produces development actions, e.g., edits or comments. |
This state-intent-action formalism enables us to capture many different tasks in a general way. What’s more, DevScript is a concise way to express complex actions, without the need to output the whole state (the original code) as it would be after the action takes place; this makes the model more efficient and more interpretable. For example, a rename might touch a file in dozens of places, but a model can predict a single rename action.
An ML peer programmer
DIDACT does a good job on individual assistive tasks. For example, below we show DIDACT doing code clean-up after functionality is mostly done. It looks at the code along with some final comments by the code reviewer (marked with “human” in the animation), and predicts edits to address those comments (rendered as a diff).
 |
| Given an initial snippet of code and the comments that a code reviewer attached to that snippet, the Pre-Submit Cleanup task of DIDACT produces edits (insertions and deletions of text) that address those comments. |
The multimodal nature of DIDACT also gives rise to some surprising capabilities, reminiscent of behaviors emerging with scale. One such capability is history augmentation, which can be enabled via prompting. Knowing what the developer did recently enables the model to make a better guess about what the developer should do next.
 |
| An illustration of history-augmented code completion in action. |
A powerful such task exemplifying this capability is history-augmented code completion. In the figure below, the developer adds a new function parameter (1), and moves the cursor into the documentation (2). Conditioned on the history of developer edits and the cursor position, the model completes the line (3) by correctly predicting the docstring entry for the new parameter.
 |
| An illustration of edit prediction, over multiple chained iterations. |
In an even more powerful history-augmented task, edit prediction, the model can choose where to edit next in a fashion that is historically consistent. If the developer deletes a function parameter (1), the model can use history to correctly predict an update to the docstring (2) that removes the deleted parameter (without the human developer manually placing the cursor there) and to update a statement in the function (3) in a syntactically (and — arguably — semantically) correct way. With history, the model can unambiguously decide how to continue the “editing video” correctly. Without history, the model wouldn’t know whether the missing function parameter is intentional (because the developer is in the process of a longer edit to remove it) or accidental (in which case the model should re-add it to fix the problem).
The model can go even further. For example, we started with a blank file and asked the model to successively predict what edits would come next until it had written a full code file. The astonishing part is that the model developed code in a step-by-step way that would seem natural to a developer: It started by first creating a fully working skeleton with imports, flags, and a basic main function. It then incrementally added new functionality, like reading from a file and writing results, and added functionality to filter out some lines based on a user-provided regular expression, which required changes across the file, like adding new flags.
Conclusion
DIDACT turns Google’s software development process into training demonstrations for ML developer assistants, and uses those demonstrations to train models that construct code in a step-by-step fashion, interactively with tools and code reviewers. These innovations are already powering tools enjoyed by Google developers every day. The DIDACT approach complements the great strides taken by large language models at Google and elsewhere, towards technologies that ease toil, improve productivity, and enhance the quality of work of software engineers.
Acknowledgements
This work is the result of a multi-year collaboration among Google Research, Google Core Systems and Experiences, and DeepMind. We would like to acknowledge our colleagues Jacob Austin, Pascal Lamblin, Pierre-Antoine Manzagol, and Daniel Zheng, who join us as the key drivers of this project. This work could not have happened without the significant and sustained contributions of our partners at Alphabet (Peter Choy, Henryk Michalewski, Subhodeep Moitra, Malgorzata Salawa, Vaibhav Tulsyan, and Manushree Vijayvergiya), as well as the many people who collected data, identified tasks, built products, strategized, evangelized, and helped us execute on the many facets of this agenda (Ankur Agarwal, Paige Bailey, Marc Brockschmidt, Rodrigo Damazio Bovendorp, Satish Chandra, Savinee Dancs, Matt Frazier, Alexander Frömmgen, Nimesh Ghelani, Chris Gorgolewski, Chenjie Gu, Vincent Hellendoorn, Franjo Ivančić, Marko Ivanković, Emily Johnston, Luka Kalinovcic, Lera Kharatyan, Jessica Ko, Markus Kusano, Kathy Nix, Sara Qu, Marc Rasi, Marcus Revaj, Ballie Sandhu, Michael Sloan, Tom Small, Gabriela Surita, Maxim Tabachnyk, David Tattersall, Sara Toth, Kevin Villela, Sara Wiltberger, and Donald Duo Zhao) and our extremely supportive leadership (Martín Abadi, Joelle Barral, Jeff Dean, Madhura Dudhgaonkar, Douglas Eck, Zoubin Ghahramani, Hugo Larochelle, Chandu Thekkath, and Niranjan Tulpule). Thank you!
[ad_2]
Source link