[ad_1]
Building models that solve a diverse set of tasks has become a dominant paradigm in the domains of vision and language. In natural language processing, large pre-trained models, such as PaLM, GPT-3 and Gopher, have demonstrated remarkable zero-shot learning of new language tasks. Similarly, in computer vision, models like CLIP and Flamingo have shown robust performance on zero-shot classification and object recognition. A natural next step is to use such tools to construct agents that can complete different decision-making tasks across many environments.
However, training such agents faces the inherent challenge of environmental diversity, since different environments operate with distinct state action spaces (e.g., the joint space and continuous controls in MuJoCo are fundamentally different from the image space and discrete actions in Atari). This environmental diversity hampers knowledge sharing, learning, and generalization across tasks and environments. Furthermore, it is difficult to construct reward functions across environments, as different tasks generally have different notions of success.
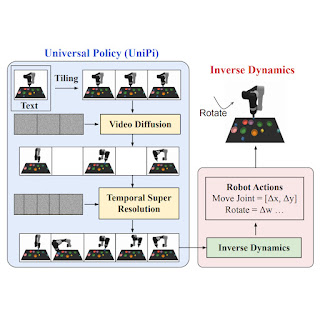
In “Learning Universal Policies via Text-Guided Video Generation”, we propose a Universal Policy (UniPi) that addresses environmental diversity and reward specification challenges. UniPi leverages text for expressing task descriptions and video (i.e., image sequences) as a universal interface for conveying action and observation behavior in different environments. Given an input image frame paired with text describing a current goal (i.e., the next high-level step), UniPi uses a novel video generator (trajectory planner) to generate video with snippets of what an agent’s trajectory should look like to achieve that goal. The generated video is fed into an inverse dynamics model that extracts underlying low-level control actions, which are then executed in simulation or by a real robot agent. We demonstrate that UniPi enables the use of language and video as a universal control interface for generalizing to novel goals and tasks across diverse environments.
 |
| Video policies generated by UniPi. |
 |
| UniPi may be applied to downstream multi-task settings that require combinatorial language generalization, long-horizon planning, or internet-scale knowledge. In the bottom example, UniPi takes the image of the white robot arm from the internet and generates video snippets according to the text description of the goal. |
UniPi implementation
To generate a valid and executable plan, a text-to-video model must synthesize a constrained video plan starting at the current observed image. We found it more effective to explicitly constrain a video synthesis model during training (as opposed to only constraining videos at sampling time) by providing the first frame of each video as explicit conditioning context.
At a high level, UniPi has four major components: 1) consistent video generation with first-frame tiling, 2) hierarchical planning through temporal super resolution, 3) flexible behavior synthesis, and 4) task-specific action adaptation. We explain the implementation and benefit of each component in detail below.
Video generation through tiling
Existing text-to-video models like Imagen typically generate videos where the underlying environment state changes significantly throughout the duration. To construct an accurate trajectory planner, it is important that the environment remains consistent across all time points. We enforce environment consistency in conditional video synthesis by providing the observed image as additional context when denoising each frame in the synthesized video. To achieve context conditioning, UniPi directly concatenates each intermediate frame sampled from noise with the conditioned observed image across sampling steps, which serves as a strong signal to maintain the underlying environment state across time.
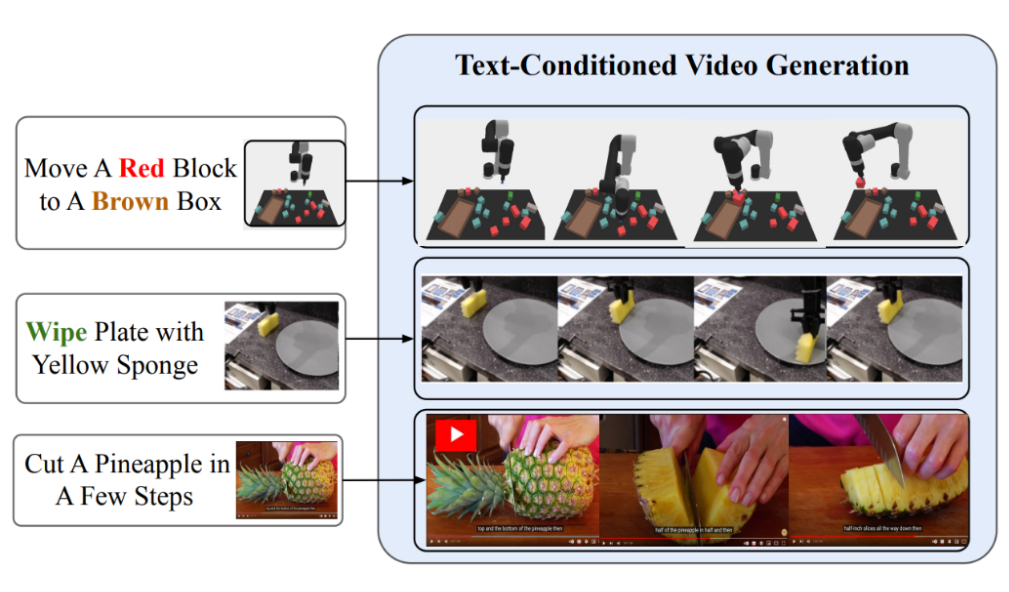 |
| Text-conditional video generation enables UniPi to train general purpose policies on a wide range of data sources (simulated, real robots and YouTube). |
Hierarchical planning
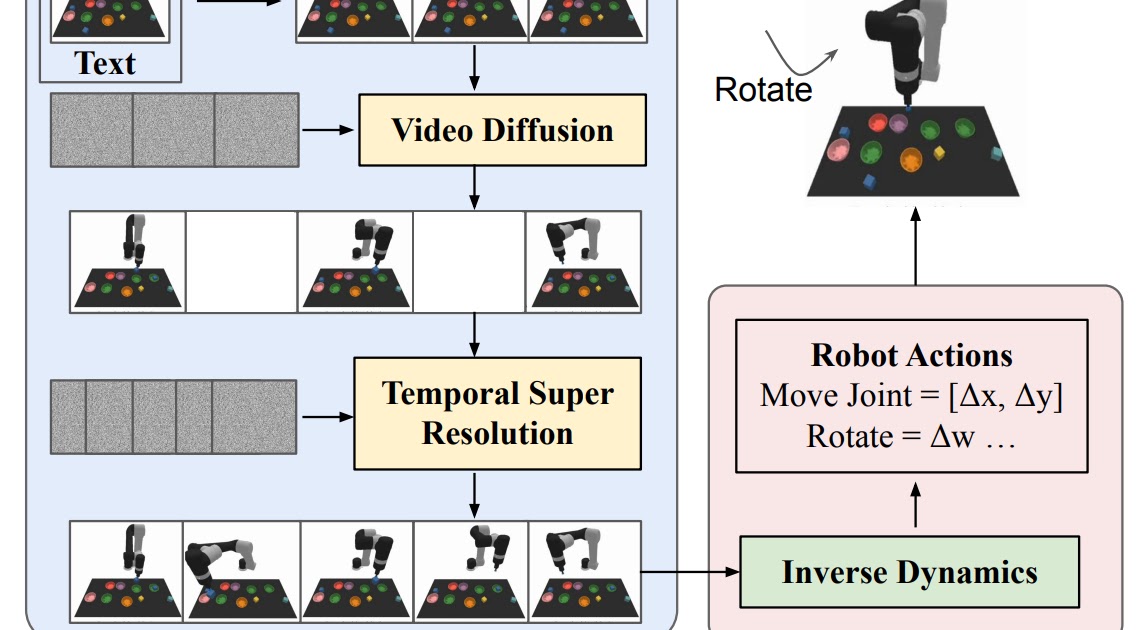
When constructing plans in high-dimensional environments with long time horizons, directly generating a set of actions to reach a goal state quickly becomes intractable due to the exponential growth of the underlying search space as the plan gets longer. Planning methods often circumvent this issue by leveraging a natural hierarchy in planning. Specifically, planning methods first construct coarse plans (the intermediate key frames spread out across time) operating on low-dimensional states and actions, which are then refined into plans in the underlying state and action spaces.
Similar to planning, our conditional video generation procedure exhibits a natural temporal hierarchy. UniPi first generates videos at a coarse level by sparsely sampling videos (“abstractions”) of desired agent behavior along the time axis. UniPi then refines the videos to represent valid behavior in the environment by super-resolving videos across time. Meanwhile, coarse-to-fine super-resolution further improves consistency via interpolation between frames.
 |
| Given an input observation and text instruction, we plan a set of images representing agent behavior. Images are converted to actions using an inverse dynamics model. |
Flexible behavioral modulation
When planning a sequence of actions for a given sub-goal, one can readily incorporate external constraints to modulate a generated plan. Such test-time adaptability can be implemented by composing a probabilistic prior incorporating properties of the desired plan to specify desired constraints across the synthesized action trajectory, which is also compatible with UniPi. In particular, the prior can be specified using a learned classifier on images to optimize a particular task, or as a Dirac delta distribution on a particular image to guide a plan towards a particular set of states. To train the text-conditioned video generation model, we utilize the video diffusion algorithm, where pre-trained language features from the Text-To-Text Transfer Transformer (T5) are encoded.
Task-specific action adaptation
Given a set of synthesized videos, we train a small task-specific inverse dynamics model to translate frames into a set of low-level control actions. This is independent from the planner and can be done on a separate, smaller and potentially suboptimal dataset generated by a simulator.
Given the input frame and text description of the current goal, the inverse dynamics model synthesizes image frames and generates a control action sequence that predicts the corresponding future actions. An agent then executes inferred low-level control actions via closed-loop control.
Capabilities and evaluation of UniPi
We measure the task success rate on novel language-based goals, and find that UniPi generalizes well to both seen and novel combinations of language prompts, compared to baselines such as Transformer BC, Trajectory Transformer (TT), and Diffuser.
 |
| UniPi generalizes well to both seen and novel combinations of language prompts in Place (e.g., “place X in Y”) and Relation (e.g., “place X to the left of Y”) tasks. |
Below, we illustrate generated videos on unseen combinations of goals. UniPi is able to synthesize a diverse set of behaviors that satisfy unseen language subgoals:
 |
| Generated videos for unseen language goals at test time. |
Multi-environment transfer
We measure the task success rate of UniPi and baselines on novel tasks not seen during training. UniPi again outperforms the baselines by a large margin:
 |
| UniPi generalizes well to new environments when trained on a set of different multi-task environments. |
Below, we illustrate generated videos on unseen tasks. UniPi is further able to synthesize a diverse set of behaviors that satisfy unseen language tasks:
 |
| Generated video plans on different new test tasks in the multitask setting. |
Real world transfer
Below, we further illustrate generated videos given language instructions on unseen real images. Our approach is able to synthesize a diverse set of different behaviors which satisfy language instructions:
 |
Using internet pre-training enables UniPi to synthesize videos of tasks not seen during training. In contrast, a model trained from scratch incorrectly generates plans of different tasks:
 |
To evaluate the quality of videos generated by UniPi when pre-trained on non-robot data, we use the Fréchet Inception Distance (FID) and Fréchet Video Distance (FVD) metrics. We used Contrastive Language-Image Pre-training scores (CLIPScores) to measure the language-image alignment. We demonstrate that pre-trained UniPi achieves significantly higher FID and FVD scores and a better CLIPScore compared to UniPi without pre-training, suggesting that pre-training on non-robot data helps with generating plans for robots. We report the CLIPScore, FID, and VID scores for UniPi trained on Bridge data, with and without pre-training:
| Model (24×40) | CLIPScore ↑ | FID ↓ | FVD ↓ | ||||||||
| No pre-training | 24.43 ± 0.04 | 17.75 ± 0.56 | 288.02 ± 10.45 | ||||||||
| Pre-trained | 24.54 ± 0.03 | 14.54 ± 0.57 | 264.66 ± 13.64 |
| Using existing internet data improves video plan predictions under all metrics considered. |
The future of large-scale generative models for decision making
The positive results of UniPi point to the broader direction of using generative models and the wealth of data on the internet as powerful tools to learn general-purpose decision making systems. UniPi is only one step towards what generative models can bring to decision making. Other examples include using generative foundation models to provide photorealistic or linguistic simulators of the world in which artificial agents can be trained indefinitely. Generative models as agents can also learn to interact with complex environments such as the internet, so that much broader and more complex tasks can eventually be automated. We look forward to future research in applying internet-scale foundation models to multi-environment and multi-embodiment settings.
Acknowledgements
We’d like to thank all remaining authors of the paper including Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. We would like to thank George Tucker, Douglas Eck, and Vincent Vanhoucke for the feedback on this post and on the original paper.
[ad_2]
Source link