[ad_1]
Large Language Models (LLMs) like PaLM or GPT-3 showed that scaling transformers to hundreds of billions of parameters improves performance and unlocks emergent abilities. The biggest dense models for image understanding, however, have reached only 4 billion parameters, despite research indicating that promising multimodal models like PaLI continue to benefit from scaling vision models alongside their language counterparts. Motivated by this, and the results from scaling LLMs, we decided to undertake the next step in the journey of scaling the Vision Transformer.
In “Scaling Vision Transformers to 22 Billion Parameters”, we introduce the biggest dense vision model, ViT-22B. It is 5.5x larger than the previous largest vision backbone, ViT-e, which has 4 billion parameters. To enable this scaling, ViT-22B incorporates ideas from scaling text models like PaLM, with improvements to both training stability (using QK normalization) and training efficiency (with a novel approach called asynchronous parallel linear operations). As a result of its modified architecture, efficient sharding recipe, and bespoke implementation, it was able to be trained on Cloud TPUs with a high hardware utilization1. ViT-22B advances the state of the art on many vision tasks using frozen representations, or with full fine-tuning. Further, the model has also been successfully used in PaLM-e, which showed that a large model combining ViT-22B with a language model can significantly advance the state of the art in robotics tasks.
Architecture
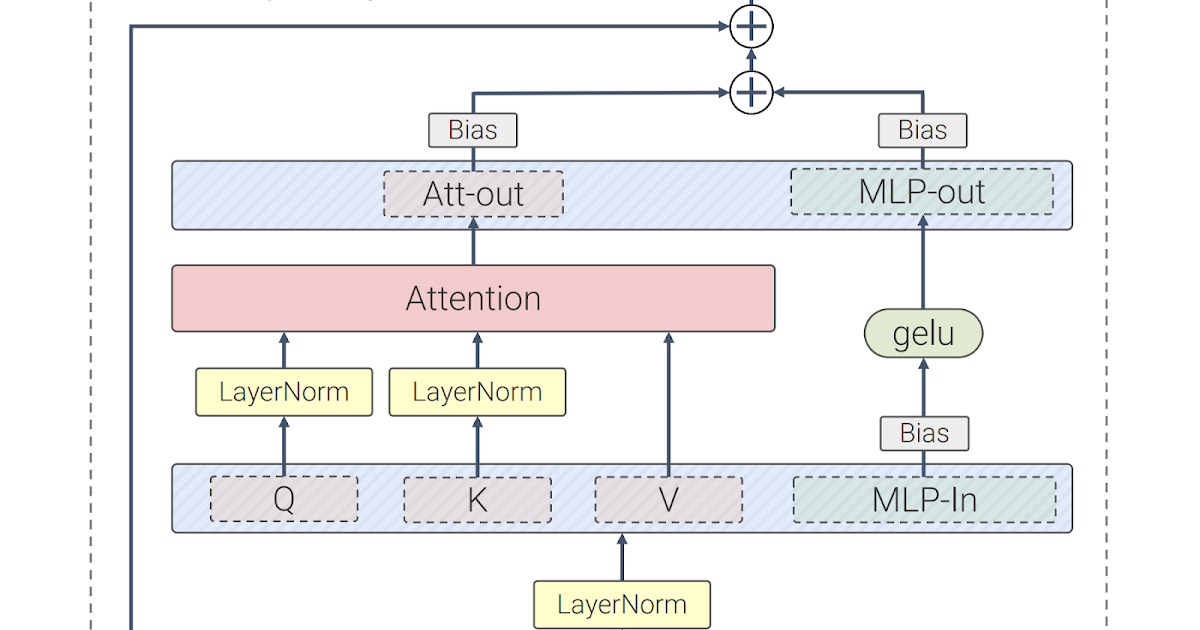
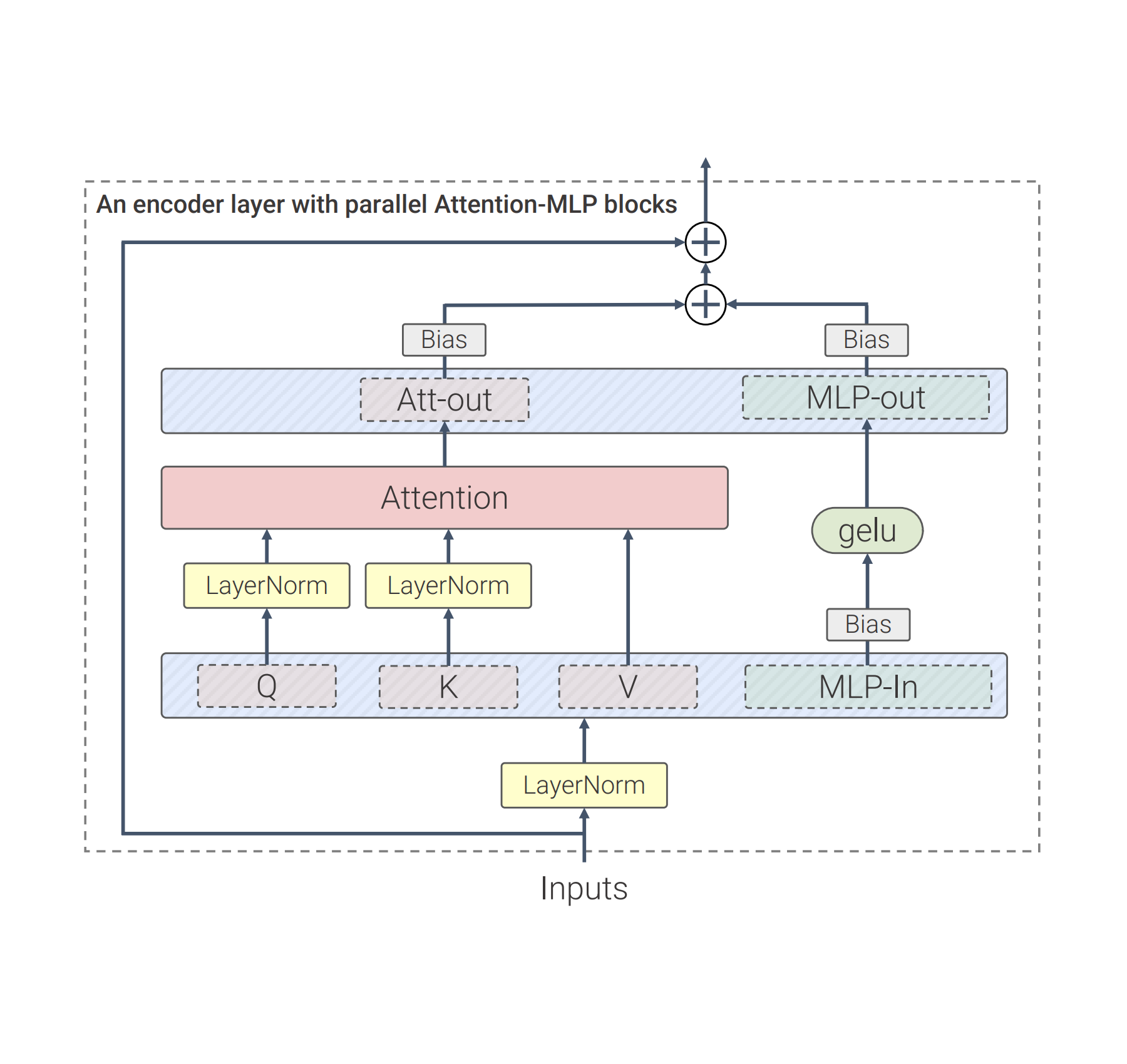
Our work builds on many advances from LLMs, such as PaLM and GPT-3. Compared to the standard Vision Transformer architecture, we use parallel layers, an approach in which attention and MLP blocks are executed in parallel, instead of sequentially as in the standard Transformer. This approach was used in PaLM and reduced training time by 15%.
Secondly, ViT-22B omits biases in the QKV projections, part of the self-attention mechanism, and in the LayerNorms, which increases utilization by 3%. The diagram below shows the modified transformer architecture used in ViT-22B:
 |
| ViT-22B transformer encoder architecture uses parallel feed-forward layers, omits biases in QKV and LayerNorm layers and normalizes Query and Key projections. |
Models at this scale necessitate “sharding” — distributing the model parameters in different compute devices. Alongside this, we also shard the activations (the intermediate representations of an input). Even something as simple as a matrix multiplication necessitates extra care, as both the input and the matrix itself are distributed across devices. We develop an approach called asynchronous parallel linear operations, whereby communications of activations and weights between devices occur at the same time as computations in the matrix multiply unit (the part of the TPU holding the vast majority of the computational capacity). This asynchronous approach minimizes the time waiting on incoming communication, thus increasing device efficiency. The animation below shows an example computation and communication pattern for a matrix multiplication.
 |
| Asynchronized parallel linear operation. The goal is to compute the matrix multiplication y = Ax, but both the matrix A and activation x are distributed across different devices. Here we illustrate how it can be done with overlapping communication and computation across devices. The matrix A is column-sharded across the devices, each holding a contiguous slice, each block represented as Aij. More details are in the paper. |
At first, the new model scale resulted in severe training instabilities. The normalization approach of Gilmer et al. (2023, upcoming) resolved these issues, enabling smooth and stable model training; this is illustrated below with example training progressions.
 |
| The effect of normalizing the queries and keys (QK normalization) in the self-attention layer on the training dynamics. Without QK normalization (red) gradients become unstable and the training loss diverges. |
Results
Here we highlight some results of ViT-22B. Note that in the paper we also explore several other problem domains, like video classification, depth estimation, and semantic segmentation.
To illustrate the richness of the learned representation, we train a text model to produce representations that align text and image representations (using LiT-tuning). Below we show several results for out-of-distribution images generated by Parti and Imagen:
 |
| Examples of image+text understanding for ViT-22B paired with a text model. The graph shows normalized probability distribution for each description of an image. |
Human object recognition alignment
To find out how aligned ViT-22B classification decisions are with human classification decisions, we evaluated ViT-22B fine-tuned with different resolutions on out-of-distribution (OOD) datasets for which human comparison data is available via the model-vs-human toolbox. This toolbox measures three key metrics: How well do models cope with distortions (accuracy)? How different are human and model accuracies (accuracy difference)? Finally, how similar are human and model error patterns (error consistency)? While not all fine-tuning resolutions perform equally well, ViT-22B variants are state of the art for all three metrics. Furthermore, the ViT-22B models also have the highest ever recorded shape bias in vision models. This means that they mostly use object shape, rather than object texture, to inform classification decisions — a strategy known from human perception (which has a shape bias of 96%). Standard models (e.g., ResNet-50, which has aa ~20–30% shape bias) often classify images like the cat with elephant texture below according to the texture (elephant); models with a high shape bias tend to focus on the shape instead (cat). While there are still many important differences between human and model perception, ViT-22B shows increased similarities to human visual object recognition.
 |
| Cat or elephant? Car or clock? Bird or bicycle? Example images with the shape of one object and the texture of a different object, used to measure shape/texture bias. |
 |
| Shape bias evaluation (higher = more shape-biased). Many vision models have a low shape / high texture bias, whereas ViT-22B fine-tuned on ImageNet (red, green, blue trained on 4B images as indicated by brackets after model names, unless trained on ImageNet only) have the highest shape bias recorded in a ML model to date, bringing them closer to a human-like shape bias. |
Out-of-distribution performance
Measuring performance on OOD datasets helps assess generalization. In this experiment we construct label-maps (mappings of labels between datasets) from JFT to ImageNet and also from ImageNet to different out-of-distribution datasets like ObjectNet (results after pre-training on this data shown in the left curve below). Then the models are fully fine-tuned on ImageNet.
We observe that scaling Vision Transformers increases OOD performance: even though ImageNet accuracy saturates, we see a significant increase on ObjectNet from ViT-e to ViT-22B (shown by the three orange dots in the upper right below).
 |
| Even though ImageNet accuracy saturates, we see a significant increase in performance on ObjectNet from ViT-e/14 to ViT-22B. |
Linear probe
Linear probe is a technique where a single linear layer is trained on top of a frozen model. Compared to full fine-tuning, this is much cheaper to train and easier to set up. We observed that the linear probe of ViT-22B performance approaches that of state-of-the-art full fine-tuning of smaller models using high-resolution images (training with higher resolution is generally much more expensive, but for many tasks it yields better results). Here are results of a linear probe trained on the ImageNet dataset and evaluated on the ImageNet validation dataset and other OOD ImageNet datasets.
Distillation
The knowledge of the bigger model can be transferred to a smaller model using the distillation method. This is helpful as big models are slower and more expensive to use. We found that ViT-22B knowledge can be transferred to smaller models like ViT-B/16 and ViT-L/16, achieving a new state of the art on ImageNet for those model sizes.
Fairness and bias
ML models can be susceptible to unintended unfair biases, such as picking up spurious correlations (measured using demographic parity) or having performance gaps across subgroups. We show that scaling up the size helps in mitigating such issues.
First, scale offers a more favorable tradeoff frontier — performance improves with scale even when the model is post-processed after training to control its level of demographic parity below a prescribed, tolerable level. Importantly, this holds not only when performance is measured in terms of accuracy, but also other metrics, such as calibration, which is a statistical measure of the truthfulness of the model’s estimated probabilities. Second, classification of all subgroups tends to improve with scale as demonstrated below. Third, ViT-22B reduces the performance gap across subgroups.
 |
 |
| Top: Accuracy for each subgroup in CelebA before debiasing. Bottom: The y-axis shows the absolute difference in performance across the two specific subgroups highlighted in this example: females and males. ViT-22B has a small gap in performance compared to smaller ViT architectures. |
Conclusions
We have presented ViT-22B, currently the largest vision transformer model at 22 billion parameters. With small but critical changes to the original architecture, we achieved excellent hardware utilization and training stability, yielding a model that advances the state of the art on several benchmarks. Great performance can be achieved using the frozen model to produce embeddings and then training thin layers on top. Our evaluations further show that ViT-22B shows increased similarities to human visual perception when it comes to shape and texture bias, and offers benefits in fairness and robustness, when compared to existing models.
Acknowledgements
This is a joint work of Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd van Steenkiste, Gamaleldin Fathy, Elsayed Aravindh Mahendran, Fisher Yu, Avital Oliver, Fantine Huot, Jasmijn Bastings, Mark Patrick Collier, Alexey Gritsenko, Vighnesh Birodkar, Cristina Vasconcelos, Yi Tay, Thomas Mensink, Alexander Kolesnikov, Filip Pavetić, Dustin Tran, Thomas Kipf, Mario Lučić, Xiaohua Zhai, Daniel Keysers Jeremiah Harmsen, and Neil Houlsby
We would like to thank Jasper Uijlings, Jeremy Cohen, Arushi Goel, Radu Soricut, Xingyi Zhou, Lluis Castrejon, Adam Paszke, Joelle Barral, Federico Lebron, Blake Hechtman, and Peter Hawkins. Their expertise and unwavering support played a crucial role in the completion of this paper. We also acknowledge the collaboration and dedication of the talented researchers and engineers at Google Research.
1Note: ViT-22B has 54.9% model FLOPs utilization (MFU) while PaLM reported
46.2% MFU and we measured 44.0% MFU for ViT-e on the same hardware. ↩
[ad_2]
Source link