[ad_1]

Recent years have seen tremendous advances across machine learning domains, from models that can explain jokes or answer visual questions in a variety of languages to those that can produce images based on text descriptions. Such innovations have been possible due to the increase in availability of large scale datasets along with novel advances that enable the training of models on these data. While scaling of robotics models has seen some success, it is outpaced by other domains due to a lack of datasets available on a scale comparable to large text corpora or image datasets.
Today we introduce PaLM-E, a new generalist robotics model that overcomes these issues by transferring knowledge from varied visual and language domains to a robotics system. We began with PaLM, a powerful large language model, and “embodied” it (the “E” in PaLM-E), by complementing it with sensor data from the robotic agent. This is the key difference from prior efforts to bring large language models to robotics — rather than relying on only textual input, with PaLM-E we train the language model to directly ingest raw streams of robot sensor data. The resulting model not only enables highly effective robot learning, but is also a state-of-the-art general-purpose visual-language model, while maintaining excellent language-only task capabilities.
An embodied language model, and also a visual-language generalist
On the one hand, PaLM-E was primarily developed to be a model for robotics, and it solves a variety of tasks on multiple types of robots and for multiple modalities (images, robot states, and neural scene representations). At the same time, PaLM-E is a generally-capable vision-and-language model. It can perform visual tasks, such as describing images, detecting objects, or classifying scenes, and is also proficient at language tasks, like quoting poetry, solving math equations or generating code.
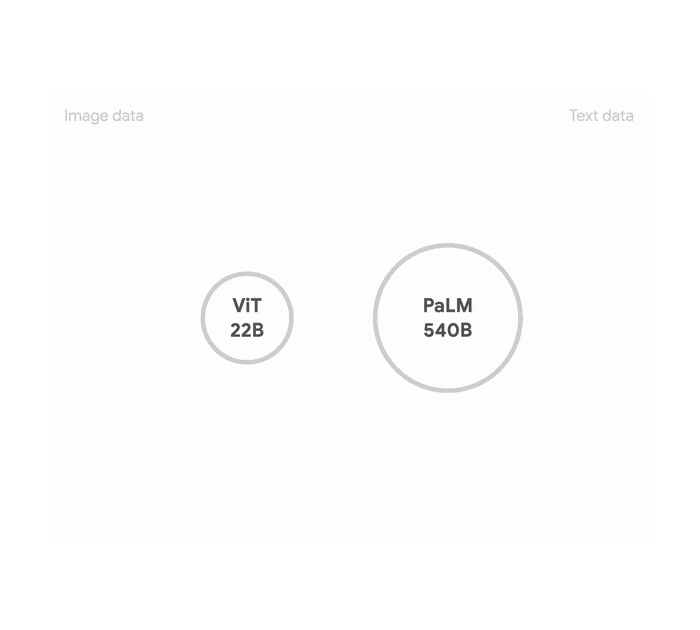
PaLM-E combines our most recent large language model, PaLM, together with one of our most advanced vision models, ViT-22B. The largest instantiation of this approach, built on PaLM-540B, is called PaLM-E-562B and sets a new state of the art on the visual-language OK-VQA benchmark, without task-specific fine-tuning, and while retaining essentially the same general language performance as PaLM-540B.
How does PaLM-E work?
Technically, PaLM-E works by injecting observations into a pre-trained language model. This is realized by transforming sensor data, e.g., images, into a representation through a procedure that is comparable to how words of natural language are processed by a language model.
Language models rely on a mechanism to represent text mathematically in a way that neural networks can process. This is achieved by first splitting the text into so-called tokens that encode (sub)words, each of which is associated with a high-dimensional vector of numbers, the token embedding. The language model is then able to apply mathematical operations (e.g., matrix multiplication) on the resulting sequence of vectors to predict the next, most likely word token. By feeding the newly predicted word back to the input, the language model can iteratively generate a longer and longer text.
The inputs to PaLM-E are text and other modalities — images, robot states, scene embeddings, etc. — in an arbitrary order, which we call “multimodal sentences”. For example, an input might look like, “What happened between <img_1> and <img_2>?”, where <img_1> and <img_2> are two images. The output is text generated auto-regressively by PaLM-E, which could be an answer to a question, or a sequence of decisions in text form.
 |
| PaLM-E model architecture, showing how PaLM-E ingests different modalities (states and/or images) and addresses tasks through multimodal language modeling. |
The idea of PaLM-E is to train encoders that convert a variety of inputs into the same space as the natural word token embeddings. These continuous inputs are mapped into something that resembles “words” (although they do not necessarily form discrete sets). Since both the word and image embeddings now have the same dimensionality, they can be fed into the language model.
We initialize PaLM-E for training with pre-trained models for both the language (PaLM) and vision components (Vision Transformer, a.k.a. ViT). All parameters of the model can be updated during training.
Transferring knowledge from large-scale training to robots
PaLM-E offers a new paradigm for training a generalist model, which is achieved by framing robot tasks and vision-language tasks together through a common representation: taking images and text as input, and outputting text. A key result is that PaLM-E attains significant positive knowledge transfer from both the vision and language domains, improving the effectiveness of robot learning.
 |
| Positive transfer of knowledge from general vision-language tasks results in more effective robot learning, shown for three different robot embodiments and domains. |
Results show that PaLM-E can address a large set of robotics, vision and language tasks simultaneously without performance degradation compared to training individual models on individual tasks. Further, the visual-language data actually significantly improves the performance of the robot tasks. This transfer enables PaLM-E to learn robotics tasks efficiently in terms of the number of examples it requires to solve a task.
Results
We evaluate PaLM-E on three robotic environments, two of which involve real robots, as well as general vision-language tasks such as visual question answering (VQA), image captioning, and general language tasks. When PaLM-E is tasked with making decisions on a robot, we pair it with a low-level language-to-action policy to translate text into low-level robot actions.
In the first example below, a person asks a mobile robot to bring a bag of chips to them. To successfully complete the task, PaLM-E produces a plan to find the drawer and open it and then responds to changes in the world by updating its plan as it executes the task. In the second example, the robot is asked to grab a green block. Even though the block has not been seen by that robot, PaLM-E still generates a step-by-step plan that generalizes beyond the training data of that robot.
 |
 |
| PaLM-E controls a mobile robot operating in a kitchen environment. Left: The task is to get a chip bag. PaLM-E shows robustness against adversarial disturbances, such as putting the chip bag back into the drawer. Right: The final steps of executing a plan to retrieve a previously unseen block (green star). This capability is facilitated by transfer learning from the vision and language models. |
In the second environment below, the same PaLM-E model solves very long-horizon, precise tasks, such as “sort the blocks by colors into corners,” on a different type of robot. It directly looks at the images and produces a sequence of shorter textually-represented actions — e.g., “Push the blue cube to the bottom right corner,” “Push the blue triangle there too.” — long-horizon tasks that were out of scope for autonomous completion, even in our own most recent models. We also demonstrate the ability to generalize to new tasks not seen during training time (zero-shot generalization), such as pushing red blocks to the coffee cup.
 |
 |
| PaLM-E controlling a tabletop robot to successfully complete long-horizon tasks. |
The third robot environment is inspired by the field of task and motion planning (TAMP), which studies combinatorially challenging planning tasks (rearranging objects) that confront the robot with a very high number of possible action sequences. We show that with a modest amount of training data from an expert TAMP planner, PaLM-E is not only able to also solve these tasks, but it also leverages visual and language knowledge transfer in order to more effectively do so.
 |
 |
| PaLM-E produces plans for a task and motion planning environment. |
As a visual-language generalist, PaLM-E is a competitive model, even compared with the best vision-language-only models, including Flamingo and PaLI. In particular, PaLM-E-562B achieves the highest number ever reported on the challenging OK-VQA dataset, which requires not only visual understanding but also external knowledge of the world. Further, this result is reached with a generalist model, without fine-tuning specifically on only that task.
 |
| PaLM-E exhibits capabilities like visual chain-of-thought reasoning in which the model breaks down its answering process in smaller steps, an ability that has so far only been demonstrated in the language-only domain. The model also demonstrates the ability to perform inference on multiple images although being trained on only single-image prompts. The image of the New York Knicks and Boston Celtics is under the terms CC-by-2.0 and was posted to Flickr by kowarski. The image of Kobe Bryant is in the Public Domain. The other images were taken by us. |
Conclusion
PaLM-E pushes the boundaries of how generally-capable models can be trained to simultaneously address vision, language and robotics while also being capable of transferring knowledge from vision and language to the robotics domain. There are additional topics investigated in further detail in the paper, such as how to leverage neural scene representations with PaLM-E and also the extent to which PaLM-E, with greater model scale, experiences less catastrophic forgetting of its language capabilities.
PaLM-E not only provides a path towards building more capable robots that benefit from other data sources, but might also be a key enabler to other broader applications using multimodal learning, including the ability to unify tasks that have so far seemed separate.
Acknowledgements
This work was done in collaboration across several teams at Google, including the Robotics at Google team and the Brain team, and with TU Berlin. Co-authors: Igor Mordatch, Andy Zeng, Aakanksha Chowdhery, Klaus Greff, Mehdi S. M. Sajjadi, Daniel Duckworth, Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Fei Xia, Brian Ichter, Karol Hausman, Tianhe Yu, Quan Vuong, Yevgen Chebotar, Wenlong Huang, Pierre Sermanet, Sergey Levine, Vincent Vanhoucke, and Marc Toussiant. Danny is a PhD student advised by Marc Toussaint at TU Berlin. We also would like to thank several other colleagues for their advice and help, including Xi Chen, Etienne Pot, Sebastian Goodman, Maria Attarian, Ted Xiao, Keerthana Gopalakrishnan, Kehang Han, Henryk Michalewski, Neil Houlsby, Basil Mustafa, Justin Gilmer, Yonghui Wu, Erica Moreira, Victor Gomes, Tom Duerig, Mario Lucic, Henning Meyer, and Kendra Byrne.
[ad_2]
Source link