[ad_1]
Overall, the high-level goals of Acme are as follows:
- To enable the reproducibility of our methods and results — this will help clarify what makes an RL problem hard or easy, something that is seldom apparent.
- To simplify the way we (and the community at large) design new algorithms — we want that next RL agent to be easier for everyone to write!
- To enhance the readability of RL agents — there should be no hidden surprises when transitioning from a paper to code.
In order to enable these goals, the design of Acme also bridges the gap between large-, medium-, and small-scale experiments. We have done so by carefully thinking about the design of agents at many different scales.
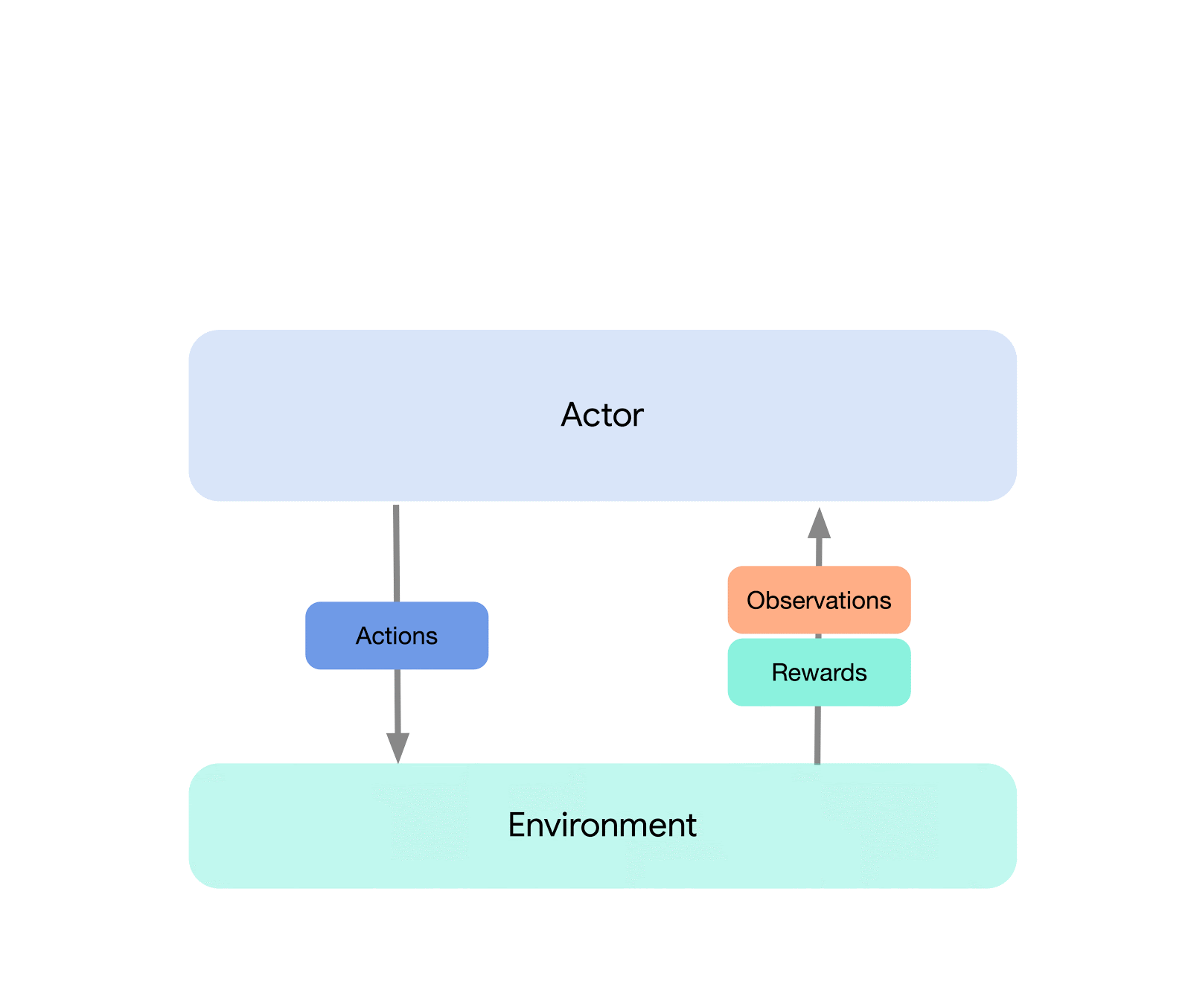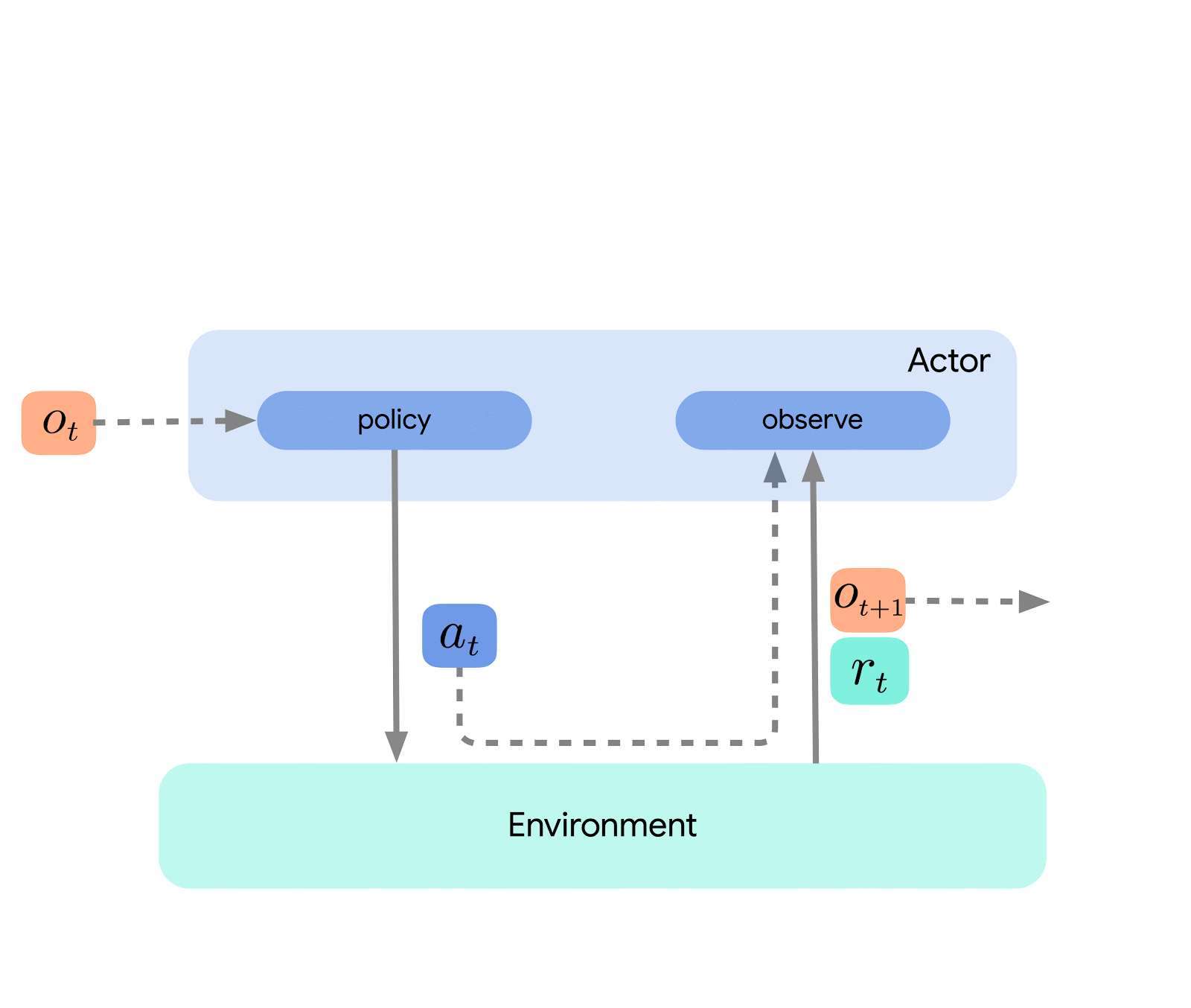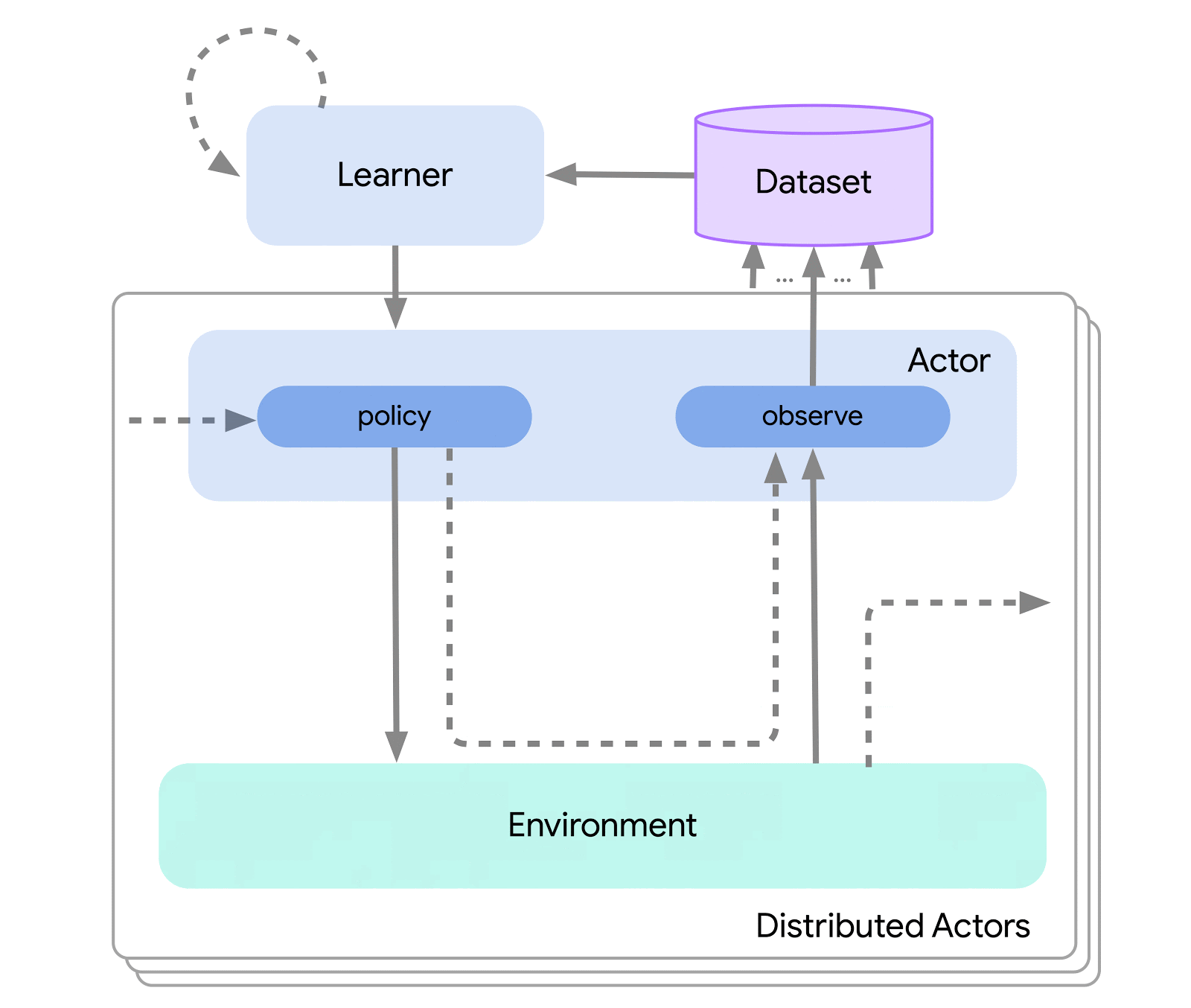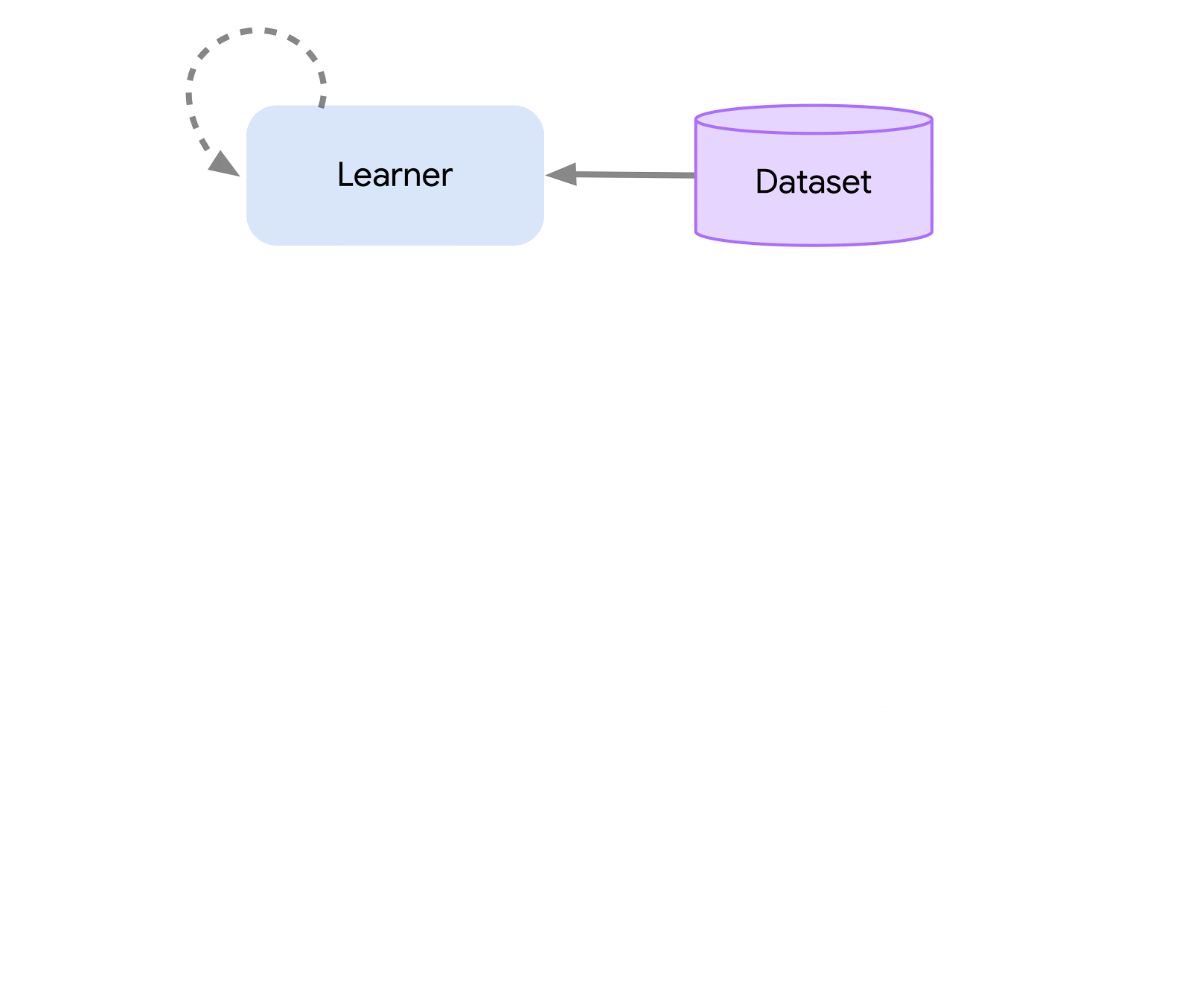
At the highest level, we can think of Acme as a classical RL interface (found in any introductory RL text) which connects an actor (i.e. an action-selecting agent) to an environment. This actor is a simple interface which has methods for selecting actions, making observations, and updating itself. Internally, learning agents further split the problem up into an “acting” and a “learning from data” component. Superficially, this allows us to re-use the acting portions across many different agents. However, more importantly this provides a crucial boundary upon which to split and parallelize the learning process. We can even scale down from here and seamlessly attack the batch RL setting where there exists no environment and only a fixed dataset. Illustrations of these different levels of complexity are shown below:
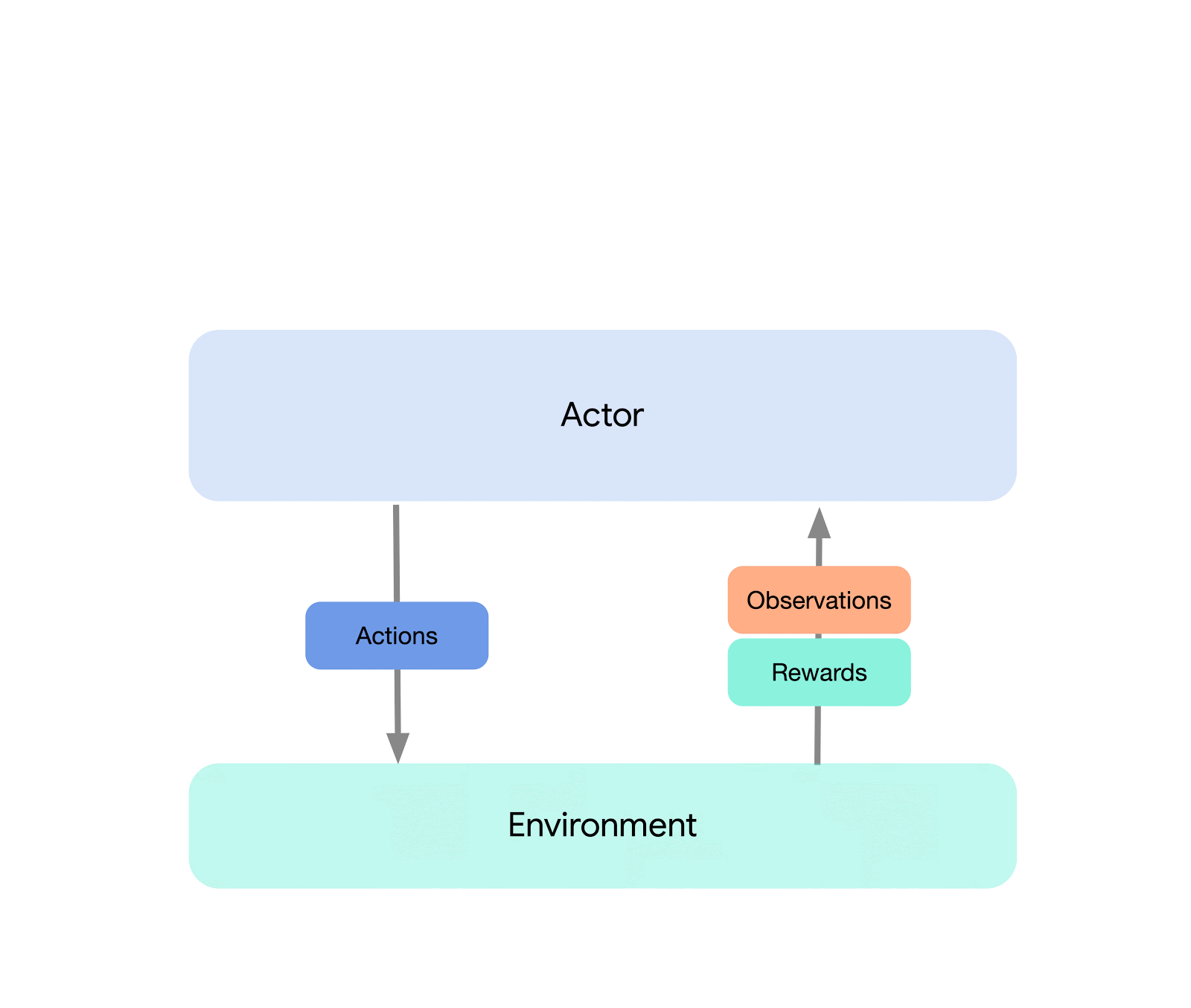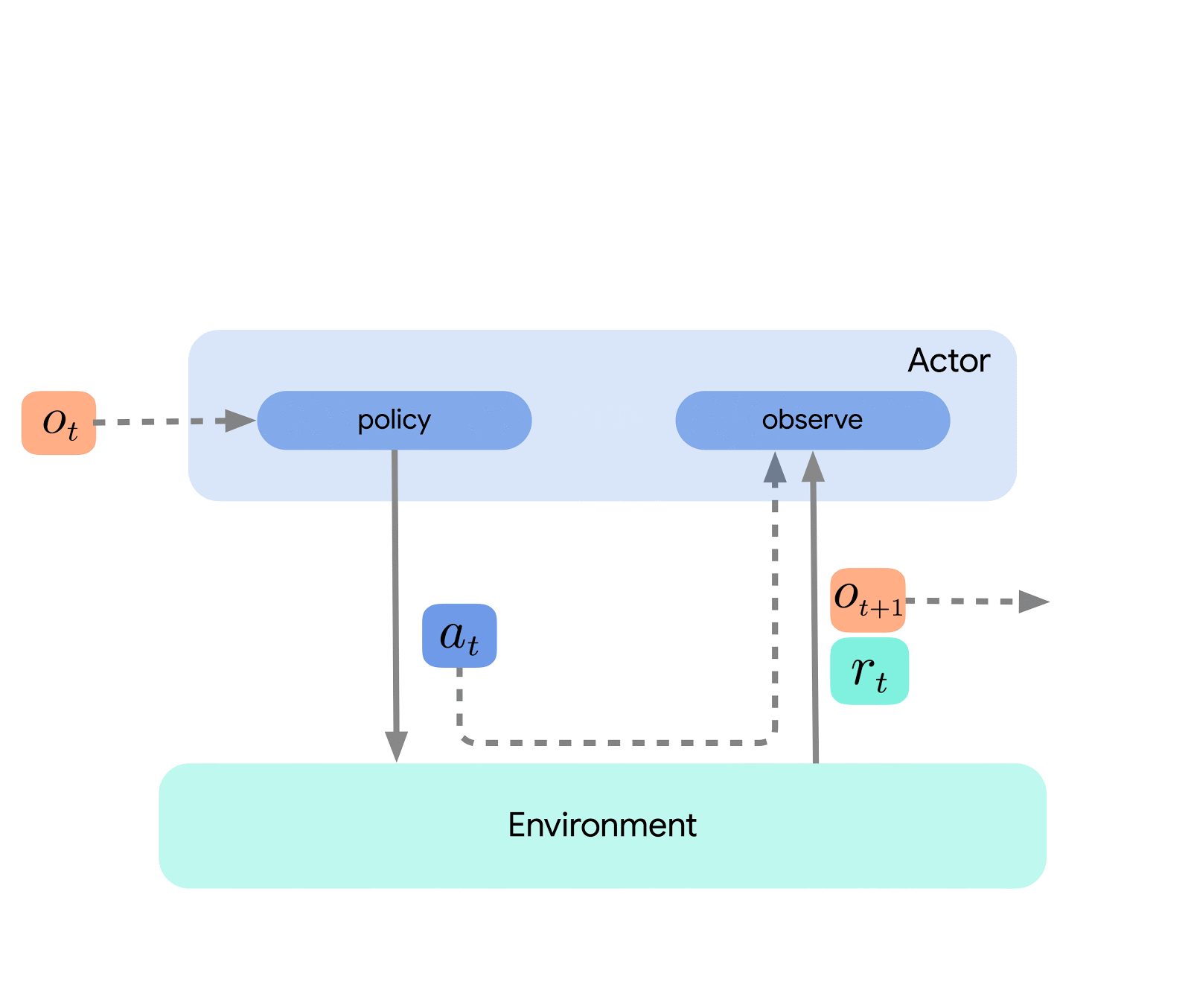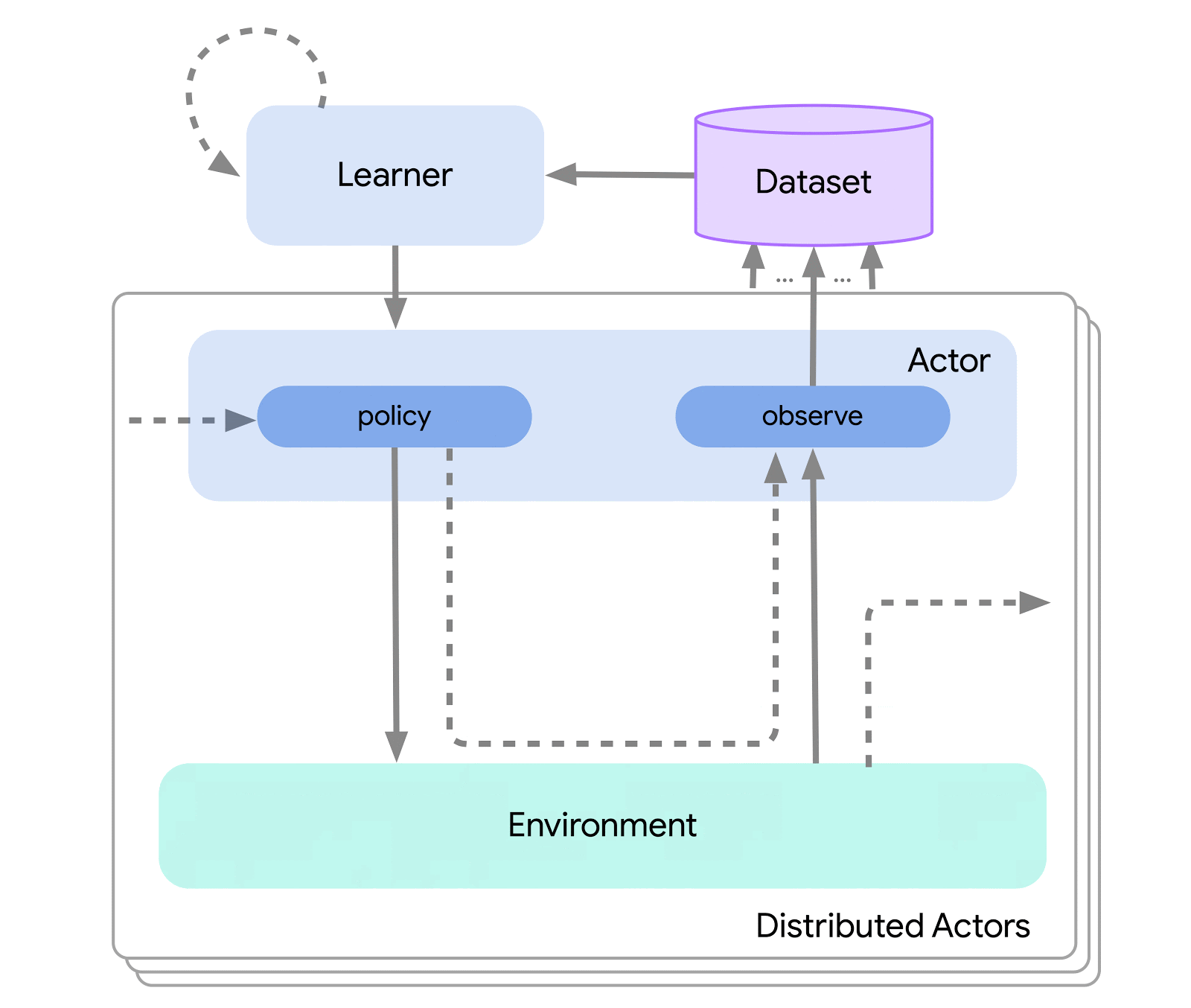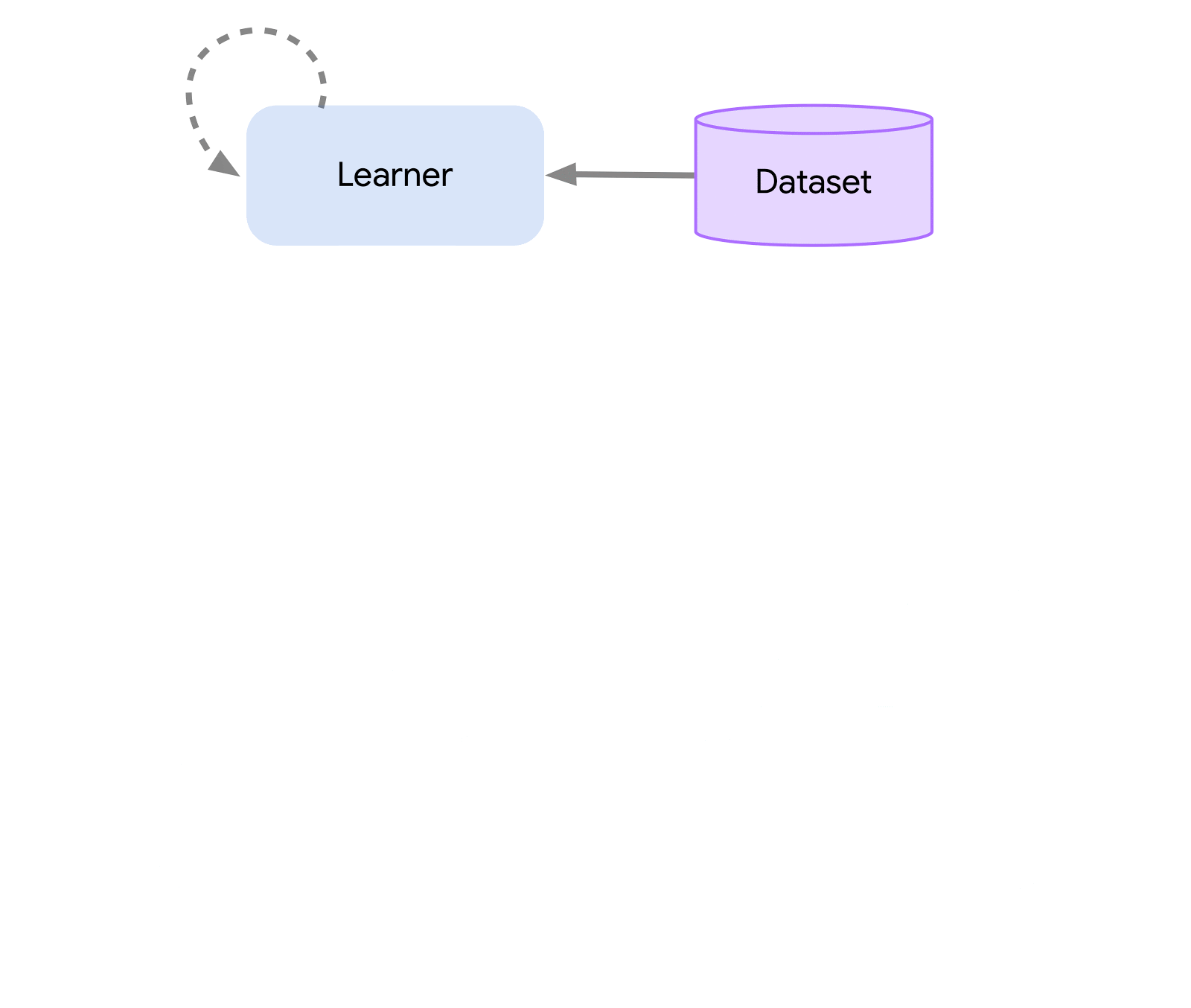
This design allows us to easily create, test, and debug novel agents in small-scale scenarios before scaling them up — all while using the same acting and learning code. Acme also provides a number of useful utilities from checkpointing, to snapshotting, to low-level computational helpers. These tools are often the unsung heroes of any RL algorithm, and in Acme we strive to keep them as simple and understandable as possible.
To enable this design Acme also makes use of Reverb: a novel, efficient data storage system purpose built for machine learning (and reinforcement learning) data. Reverb is primarily used as a system for experience replay in distributed reinforcement learning algorithms, but it also supports other data structure representations such as FIFO and priority queues. This allows us to use it seamlessly for on- and off-policy algorithms. Acme and Reverb were designed from the beginning to play nicely with one another, but Reverb is also fully usable on its own, so go check it out!
Along with our infrastructure, we are also releasing single-process instantiations of a number of agents we have built using Acme. These run the gamut from continuous control (D4PG, MPO, etc.), discrete Q-learning (DQN and R2D2), and more. With a minimal number of changes — by splitting across the acting/learning boundary — we can run these same agents in a distributed manner. Our first release focuses on single-process agents as these are the ones mostly used by students and research practitioners.
We have also carefully benchmarked these agents on a number of environments, namely the control suite, Atari, and bsuite.
Playlist of videos showing agents trained using Acme framework
While additional results are readily available in our paper, we show a few plots comparing the performance of a single agent (D4PG) when measured against both actor steps and wall clock time for a continuous control task. Due to the way in which we limit the rate at which data is inserted into replay — refer to the paper for a more in-depth discussion — we can see roughly the same performance when comparing the rewards an agent receives versus the number of interactions it has taken with the environment (actor steps). However, as the agent is further parallelised we see gains in terms of how fast the agent is able to learn. On relatively small domains, where the observations are constrained to small feature spaces, even a modest increase in this parallelisation (4 actors) results in an agent that takes under half the time to learn an optimal policy:

But for even more complex domains where the observations are images that are comparatively costly to generate we see much more extensive gains:

And the gains can be even bigger still for domains such as Atari games where the data is more expensive to collect and the learning processes generally take longer. However, it is important to note that these results share the same acting and learning code between both the distributed and non-distributed setting. So it is perfectly feasible to experiment with these agents and results at a smaller scale — in fact this is something we do all the time when developing novel agents!
For a more detailed description of this design, along with further results for our baseline agents, see our paper. Or better yet, take a look at our GitHub repository to see how you can start using Acme to simplify your own agents!
[ad_2]
Source link








