[ad_1]
In recent years, significant performance gains in autoregressive language modeling have been achieved by increasing the number of parameters in Transformer models. This has led to a tremendous increase in training energy cost and resulted in a generation of dense “Large Language Models” (LLMs) with 100+ billion parameters. Simultaneously, large datasets containing trillions of words have been collected to facilitate the training of these LLMs.
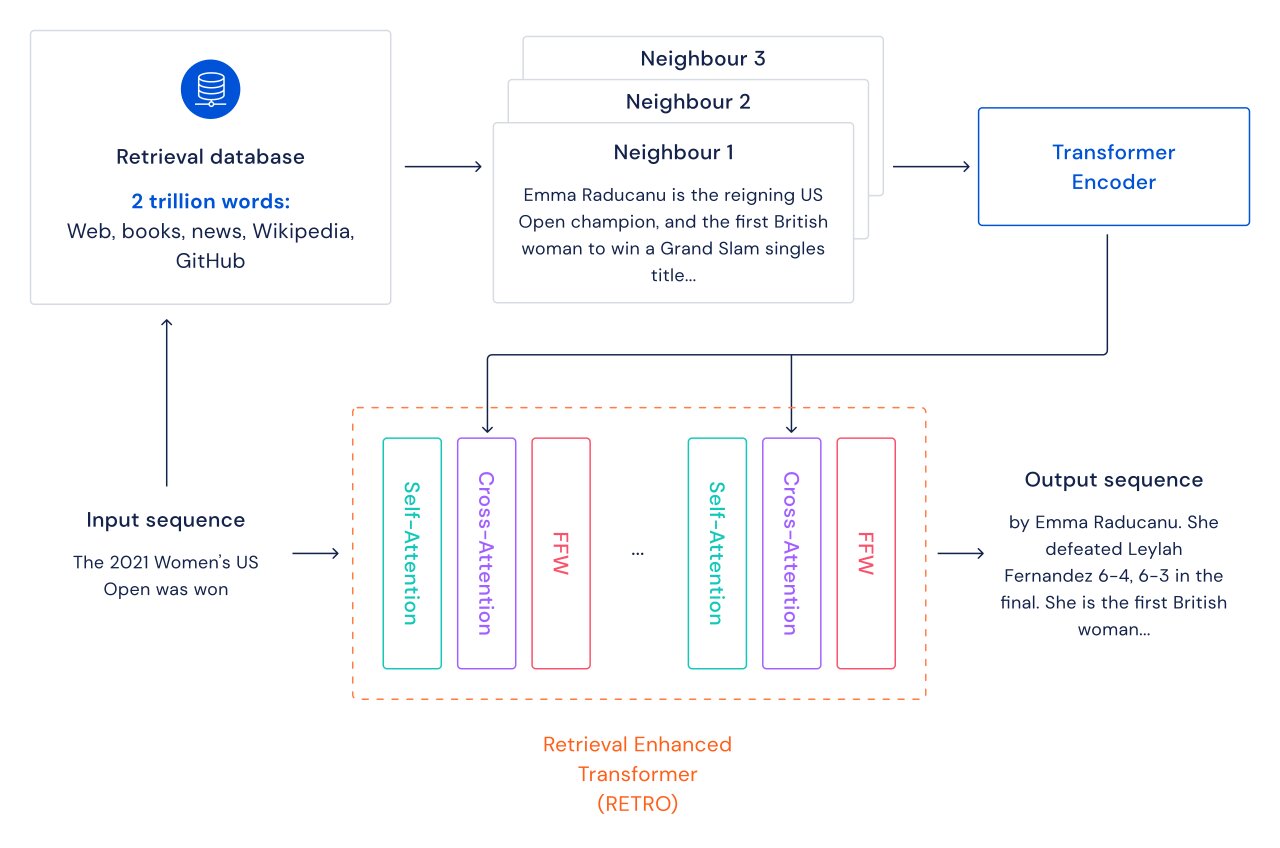
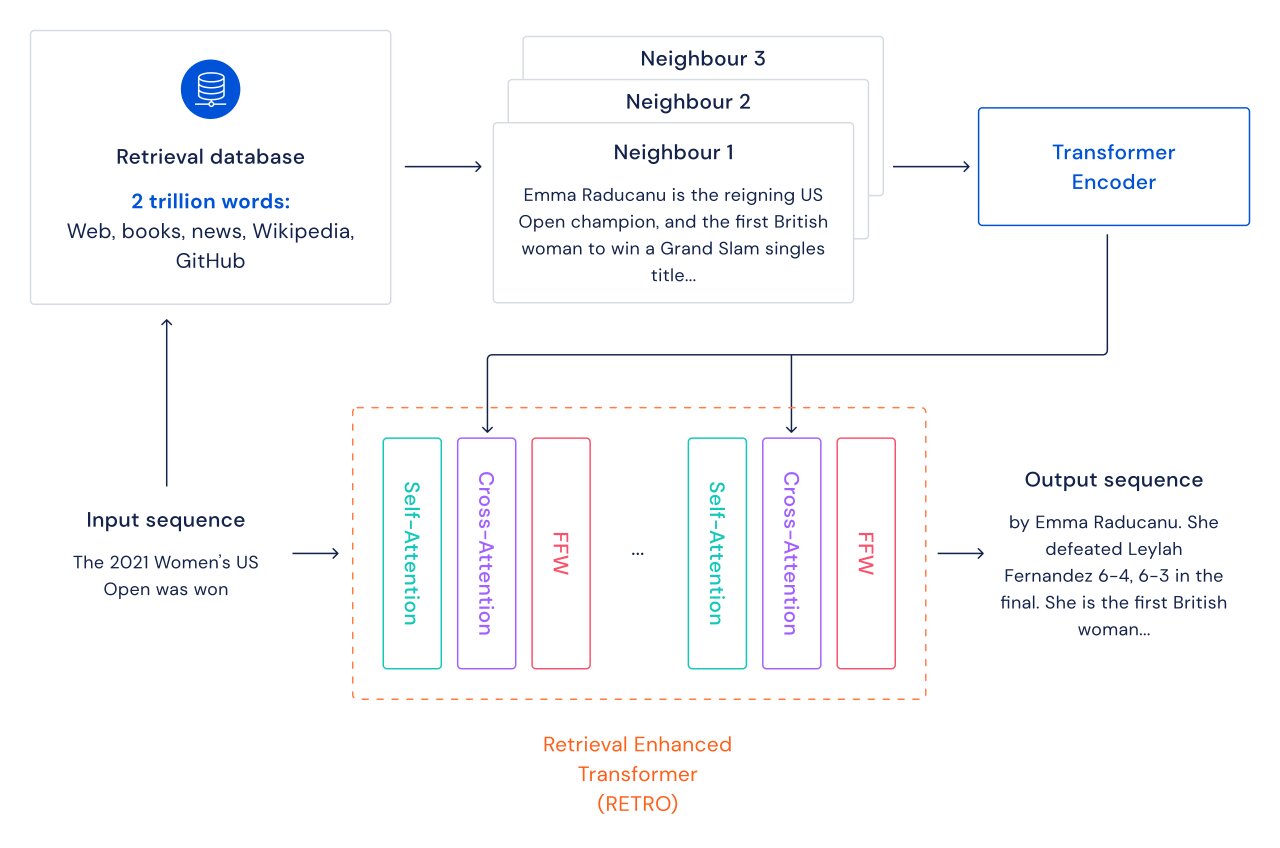
We explore an alternate path for improving language models: we augment transformers with retrieval over a database of text passages including web pages, books, news and code. We call our method RETRO, for “Retrieval Enhanced TRansfOrmers”.
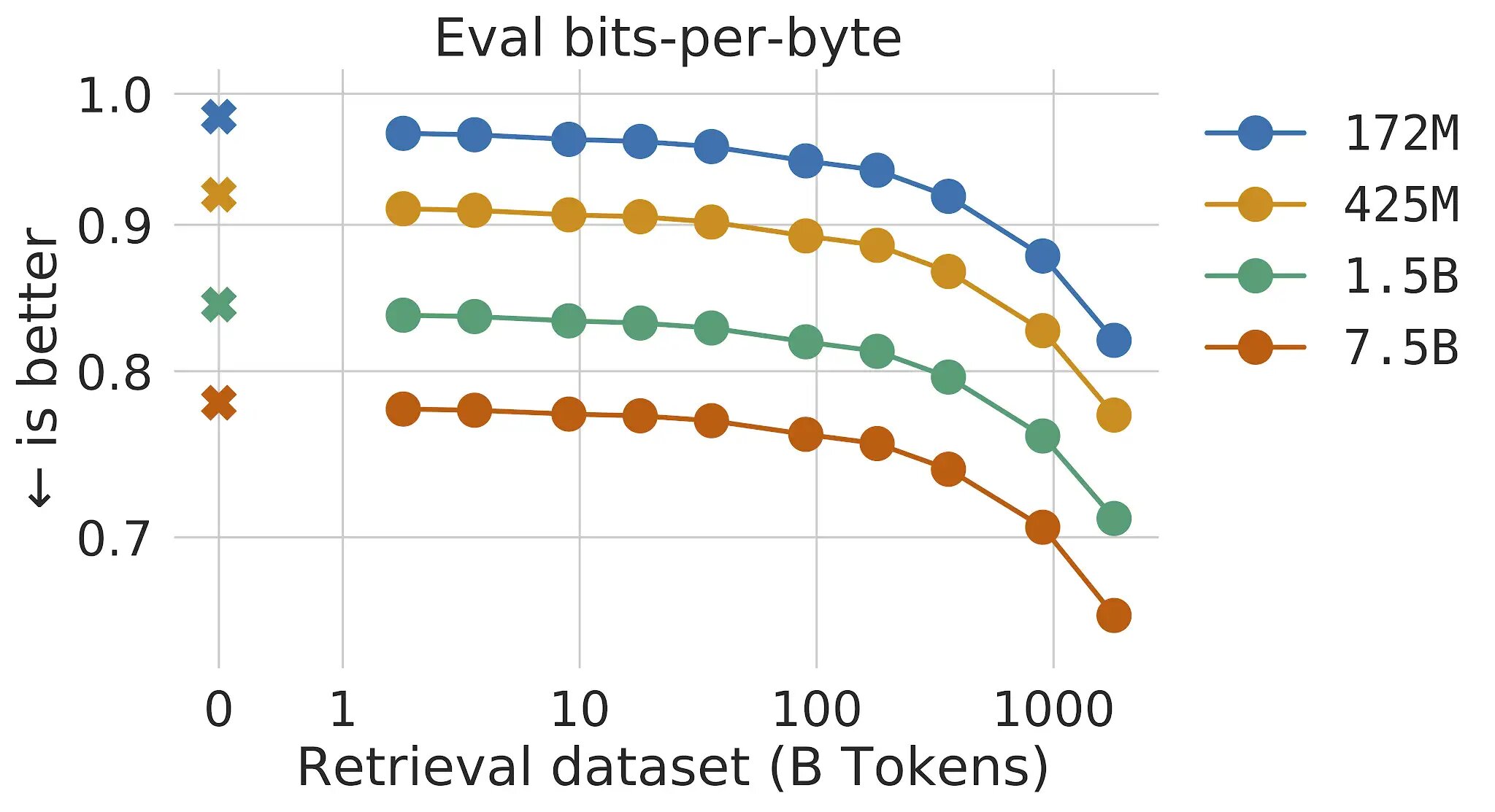
In traditional transformer language models, the benefits of model size and data size are linked: as long as the dataset is large enough, language modeling performance is limited by the size of the model. However, with RETRO the model is not limited to the data seen during training– it has access to the entire training dataset through the retrieval mechanism. This results in significant performance gains compared to a standard Transformer with the same number of parameters. We show that language modeling improves continuously as we increase the size of the retrieval database, at least up to 2 trillion tokens – 175 full lifetimes of continuous reading.
For each text passage (approximately a paragraph of a document), a nearest-neighbor search is performed which returns similar sequences found in the training database, and their continuation. These sequences help predict the continuation of the input text. The RETRO architecture interleaves regular self-attention at a document level and cross-attention with retrieved neighbors at a finer passage level. This results in both more accurate and more factual continuations. Furthermore, RETRO increases the interpretability of model predictions, and provides a route for direct interventions through the retrieval database to improve the safety of text continuation. In our experiments on the Pile, a standard language modeling benchmark, a 7.5 billion parameter RETRO model outperforms the 175 billion parameter Jurassic-1 on 10 out of 16 datasets and outperforms the 280B Gopher on 9 out of 16 datasets.
Below, we show two samples from our 7B baseline model and from our 7.5B RETRO model model that highlight how RETRO’s samples are more factual and stay more on topic than the baseline sample.


[ad_2]
Source link








