
[ad_1]
Humans are an interactive species. We interact with the physical world and with one another. For artificial intelligence (AI) to be generally helpful, it must be able to interact capably with humans and their environment. In this work we present the Multimodal Interactive Agent (MIA), which blends visual perception, language comprehension and production, navigation, and manipulation to engage in extended and often surprising physical and linguistic interactions with humans.

We build upon the approach introduced by Abramson et al. (2020), which primarily uses imitation learning to train agents. After training, MIA displays some rudimentary intelligent behaviour that we hope to later refine using human feedback. This work focuses on the creation of this intelligent behavioural prior, and we leave further feedback-based learning for future work.
We created the Playhouse environment, a 3D virtual environment composed of a randomised set of rooms and a large number of domestic interactable objects, to provide a space and setting for humans and agents to interact together. Humans and agents can interact in the Playhouse by controlling virtual robots that locomote, manipulate objects, and communicate via text. This virtual environment permits a wide range of situated dialogues, ranging from simple instructions (e.g., “Please pick up the book from the floor and place it on the blue bookshelf”) to creative play (e.g., “Bring food to the table so that we can eat”).
We collected human examples of Playhouse interactions using language games, a collection of cues prompting humans to improvise certain behaviours. In a language game one player (the setter) receives a prewritten prompt indicating a kind of task to propose to the other player (the solver). For example, the setter might receive the prompt “Ask the other player a question about the existence of an object,” and after some exploration, the setter could ask, ”Please tell me whether there is a blue duck in a room that does not also have any furniture.” To ensure sufficient behavioural diversity, we also included free-form prompts, which granted setters free choice to improvise interactions (E.g. “Now take any object that you like and hit the tennis ball off the stool so that it rolls near the clock, or somewhere near it.”). In total, we collected 2.94 years of real-time human interactions in the Playhouse.
.jpg)
Our training strategy is a combination of supervised prediction of human actions (behavioural cloning) and self-supervised learning. When predicting human actions, we found that using a hierarchical control strategy significantly improved agent performance. In this setting, the agent receives new observations roughly 4 times per second. For each observation, it produces a sequence of open-loop movement actions and optionally emits a sequence of language actions. In addition to behavioural cloning we use a form of self-supervised learning, which tasks agents with classifying whether certain vision and language inputs belong to the same or different episodes.
To evaluate agent performance, we asked human participants to interact with agents and provide binary feedback indicating whether the agent successfully carried out an instruction. MIA achieves over 70% success rate in human-rated online interactions, representing 75% of the success rate that humans themselves achieve when they play as solvers. To better understand the role of various components in MIA, we performed a series of ablations, removing, for example, visual or language inputs, the self-supervised loss, or the hierarchical control.
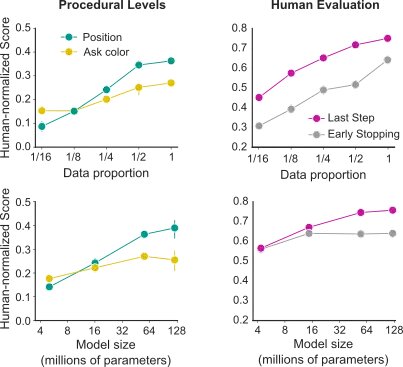
Contemporary machine learning research has uncovered remarkable regularities of performance with respect to different scale parameters; in particular, model performance scales as a power-law with dataset size, model size, and compute. These effects have been most crisply noted in the language domain, which is characterised by massive dataset sizes and highly evolved architectures and training protocols. In this work, however, we are in a decidedly different regime – with comparatively small datasets and multimodal, multi-task objective functions training heterogeneous architectures. Nevertheless, we demonstrate clear effects of scaling: as we increase dataset and model size, performance increases appreciably.
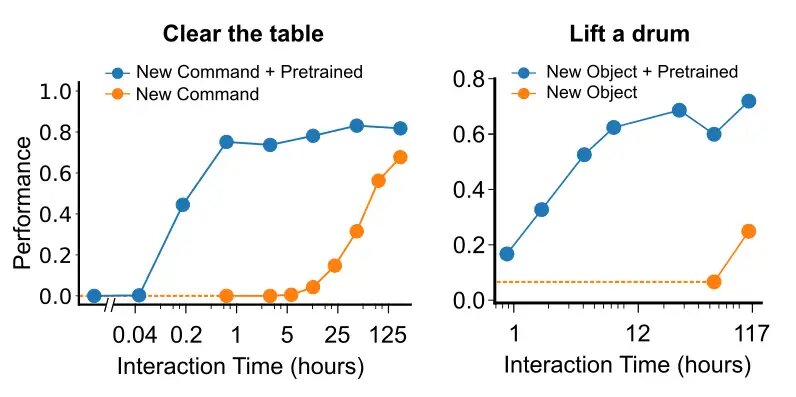
In an ideal case, training becomes more efficient given a reasonably large dataset, as knowledge is transferred between experiences. To investigate how ideal our circumstances are, we examined how much data is needed to learn to interact with a new, previously unseen object and to learn how to follow a new, previously unheard command / verb. We partitioned our data into background data and data involving a language instruction referring to the object or the verb. When we reintroduced the data referring to the new object, we found that fewer than 12 hours of human interaction was enough to acquire the ceiling performance. Analogously, when we introduced the new command or verb ‘to clear’ (i.e. to remove all objects from a surface), we found that only 1 hour of human demonstrations was enough to reach ceiling performance in tasks involving this word.
MIA exhibits startlingly rich behaviour, including a diversity of behaviours that were not preconceived by researchers, including tidying a room, finding multiple specified objects, and asking clarifying questions when an instruction is ambiguous. These interactions continually inspire us. However, the open-endedness of MIA’s behaviour presents immense challenges for quantitative evaluation. Developing comprehensive methodologies to capture and analyse open-ended behaviour in human-agent interactions will be an important focus in our future work.
For a more detailed description of our work, see our paper.
[ad_2]
Source link








