[ad_1]
In the last few years, a focus in language modelling has been on improving performance through increasing the number of parameters in transformer-based models. This approach has led to impressive results and state-of-the-art performance across many natural language processing tasks.
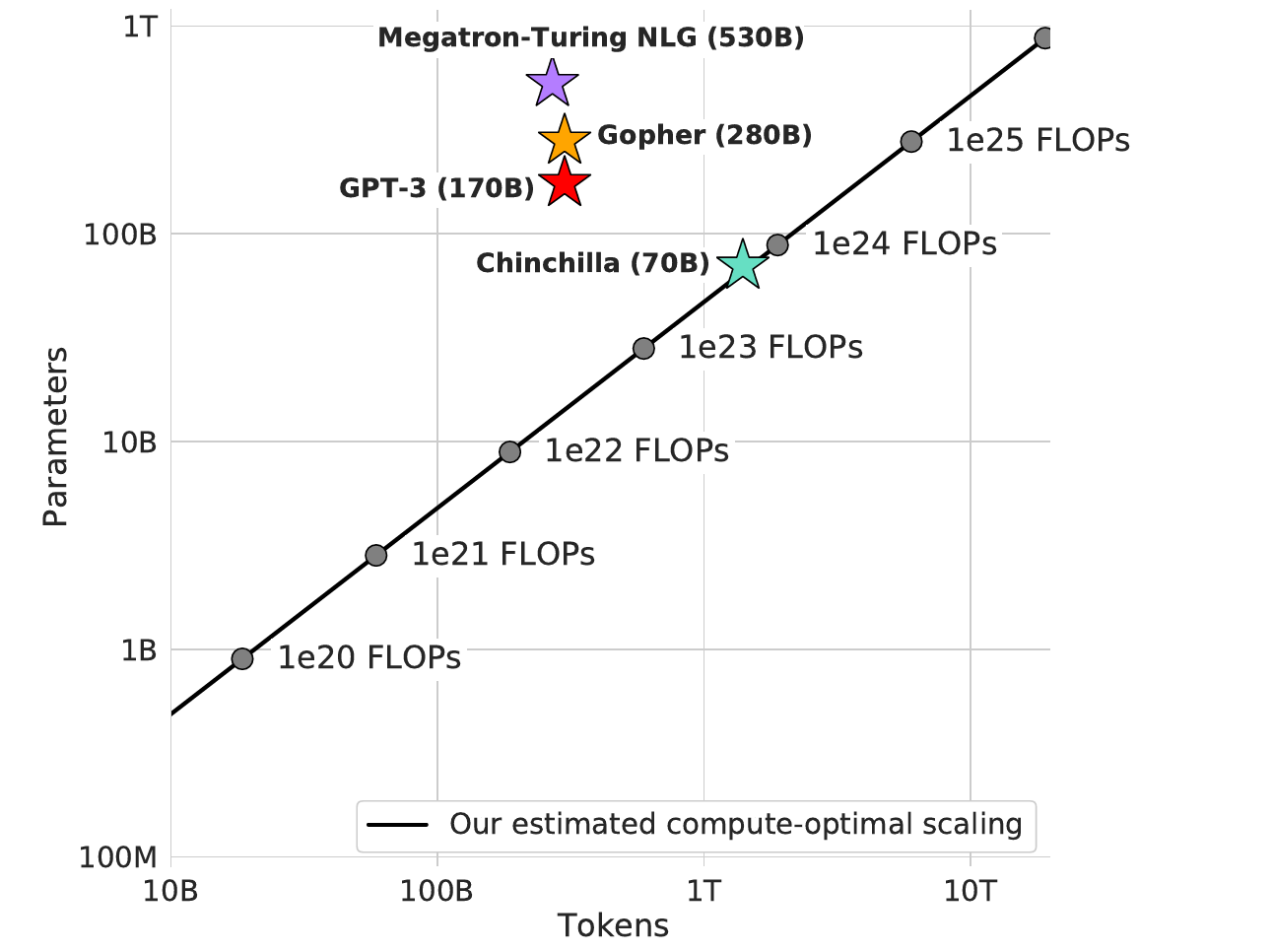
We also pursued this line of research at DeepMind and recently showcased Gopher, a 280-billion parameter model that established leading performance on a wide range of tasks including language modelling, reading comprehension, and question answering. Since then, an even larger model named Megatron-Turing NLG has been published with 530 billion parameters.
Due to the substantial cost of training these large models, it is paramount to estimate the best possible training setup to avoid wasting resources. In particular, the training compute cost for transformers is determined by two factors: the model size and the number of training tokens.
The current generation of large language models has allocated increased computational resources to increasing the parameter count of large models and keeping the training data size fixed at around 300 billion tokens. In this work, we empirically investigate the optimal tradeoff between increasing model size and the amount of training data with increasing computational resources. Specifically, we ask the question: “What is the optimal model size and number of training tokens for a given compute budget?” To answer this question, we train models of various sizes and with various numbers of tokens, and estimate this trade-off empirically.
Our main finding is that the current large language models are far too large for their compute budget and are not being trained on enough data. In fact, we find that for the number of training FLOPs used to train Gopher, a 4x smaller model trained on 4x more data would have been preferable.
.png)
We test our data scaling hypothesis by training Chinchilla, a 70-billion parameter model trained for 1.3 trillion tokens. While the training compute cost for Chinchilla and Gopher are the same, we find that it outperforms Gopher and other large language models on nearly every measured task, despite having 70 billion parameters compared to Gopher’s 280 billion.

After the release of Chinchilla, a model named PaLM was released with 540 billion parameters and trained on 768 billion tokens. This model was trained with approximately 5x the compute budget of Chinchilla and outperformed Chinchilla on a range of tasks. While the training corpus is different, our methods do predict that such a model trained on our data would outperform Chinchilla despite not being compute-optimal. Given the PaLM compute budget, we predict a 140-billion-parameter model trained on 3 trillion tokens to be optimal and more efficient for inference.
An additional benefit of smaller, more performant models is that the inference time and memory costs are reduced making querying the models both faster and possible on less hardware. In practice, while the training FLOPs between Gopher and Chinchilla are the same, the cost of using Chinchilla is substantially smaller, in addition to it performing better. Further simple optimisations may be possible that are able to continue to provide large gains.
[ad_2]
Source link








