[ad_1]
Many recent successes in language models (LMs) have been achieved within a ‘static paradigm’, where the focus is on improving performance on the benchmarks that are created without considering the temporal aspect of data. For instance, answering questions on events that the model could learn about during training, or evaluating on text sub-sampled from the same period as the training data. However, our language and knowledge are dynamic and ever evolving. Therefore, to enable a more realistic evaluation of question-answering models for the next leap in performance, it’s essential to ensure they are flexible and robust when encountering new and unseen data.
In 2021, we released Mind the Gap: Assessing Temporal Generalization in Neural Language Models and the dynamic language modelling benchmarks for WMT and arXiv to facilitate language model evaluation that take temporal dynamics into account. In this paper, we highlighted issues that current state-of-the-art large LMs face with temporal generalisation and found that knowledge-intensive tokens take a considerable performance hit.
Today, we’re releasing two papers and a new benchmark that further advance research on this topic. In StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models, we study the downstream task of question-answering on our newly proposed benchmark, StreamingQA: we want to understand how parametric and retrieval-augmented, semi-parametric question-answering models adapt to new information, in order to answer questions about new events. In Internet-augmented language models through few-shot prompting for open-domain question answering, we explore the power of combining a few-shot prompted large language model along with Google Search as a retrieval component. In doing so, we aim to improve the model’s factuality, while making sure it has access to up-to-date information for answering a diverse set of questions.
StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
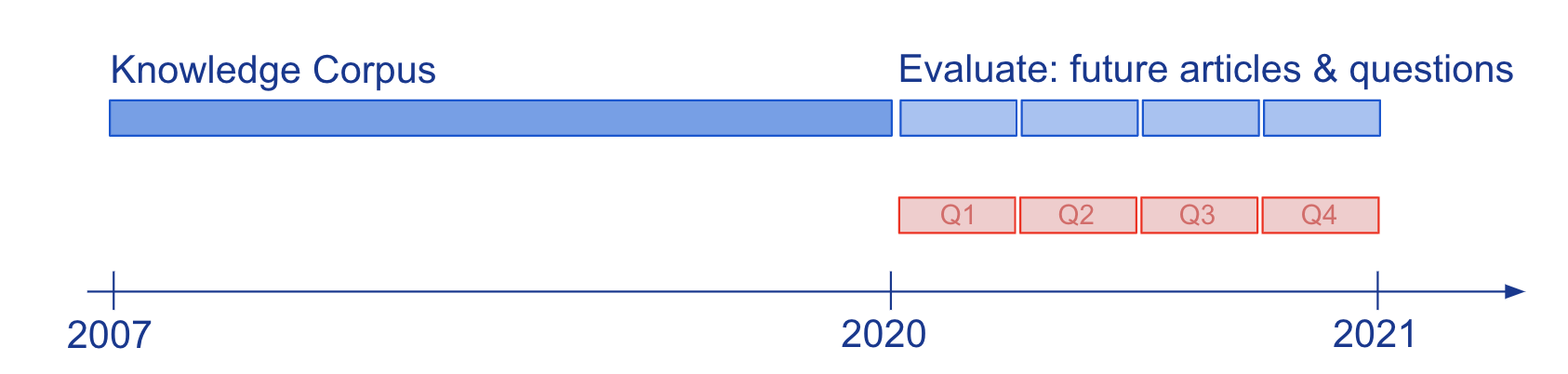
Knowledge and language understanding of models evaluated through question-answering (QA) has been commonly studied on static snapshots of knowledge, like Wikipedia. To study how semi-parametric QA models and their underlying parametric LMs adapt to evolving knowledge, we constructed the new large-scale benchmark, StreamingQA, with human-written and automatically generated questions asked on a given date, to be answered from 14 years of time-stamped news articles (see Figure 2). We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM underperform those with a retrained LM.

Internet-augmented language models through few-shot prompting for open-domain question-answering
We’re aiming to capitalise on the unique few-shot capabilities offered by large-scale language models to overcome some of their challenges, with respect to grounding to factual and up-to-date information. Motivated by semi-parametric LMs, which ground their decisions in externally retrieved evidence, we use few-shot prompting to learn to condition LMs on information returned from the web using Google Search, a broad and constantly updated knowledge source. Our approach does not involve fine-tuning or learning additional parameters, thus making it applicable to virtually any language model. And indeed, we find that LMs conditioned on the web surpass the performance of closed-book models of similar, or even larger, model size in open-domain question-answering.
[ad_2]
Source link








