[ad_1]
We’ve trained and are open-sourcing a neural net called Whisper that approaches human level robustness and accuracy on English speech recognition.
View Code
View Model Card
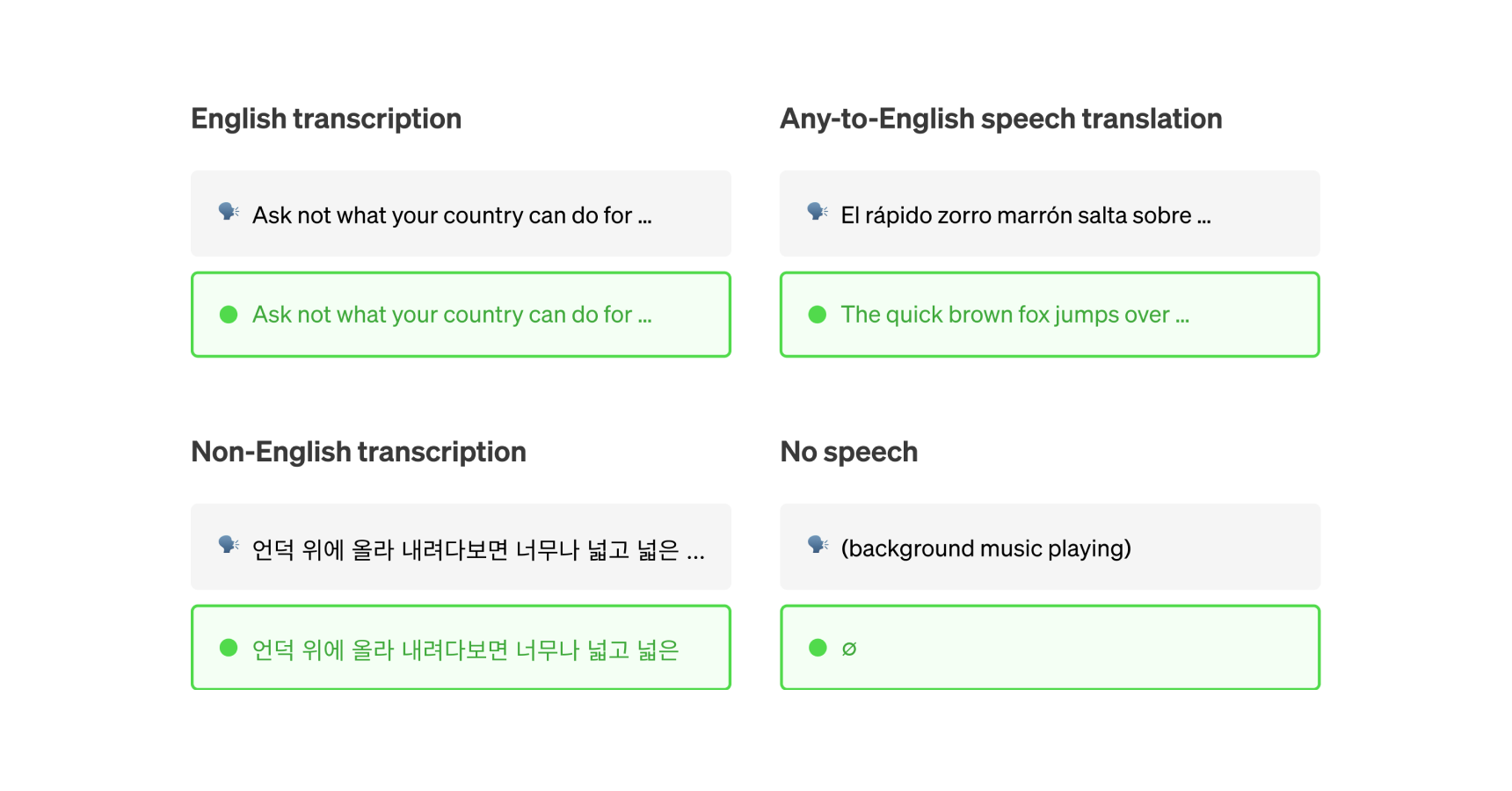
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. We show that the use of such a large and diverse dataset leads to improved robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages, as well as translation from those languages into English. We are open-sourcing models and inference code to serve as a foundation for building useful applications and for further research on robust speech processing.


The Whisper architecture is a simple end-to-end approach, implemented as an encoder-decoder Transformer. Input audio is split into 30-second chunks, converted into a log-Mel spectrogram, and then passed into an encoder. A decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.


Other existing approaches frequently use smaller, more closely paired audio-text training datasets, or use broad but unsupervised audio pretraining. Because Whisper was trained on a large and diverse dataset and was not fine-tuned to any specific one, it does not beat models that specialize in LibriSpeech performance, a famously competitive benchmark in speech recognition. However, when we measure Whisper’s zero-shot performance across many diverse datasets we find it is much more robust and makes 50% fewer errors than those models.
About a third of Whisper’s audio dataset is non-English, and it is alternately given the task of transcribing in the original language or translating to English. We find this approach is particularly effective at learning speech to text translation and outperforms the supervised SOTA on CoVoST2 to English translation zero-shot.


We hope Whisper’s high accuracy and ease of use will allow developers to add voice interfaces to a much wider set of applications. Check out the paper, model card, and code to learn more details and to try out Whisper.
[ad_2]
Source link






