[ad_1]
Skin tone is an observable characteristic that is subjective, perceived differently by individuals (e.g., depending on their location or culture) and thus is complicated to annotate. That said, the ability to reliably and accurately annotate skin tone is highly important in computer vision. This became apparent in 2018, when the Gender Shades study highlighted that computer vision systems struggled to detect people with darker skin tones, and performed particularly poorly for women with darker skin tones. The study highlights the importance for computer researchers and practitioners to evaluate their technologies across the full range of skin tones and at intersections of identities. Beyond evaluating model performance on skin tone, skin tone annotations enable researchers to measure diversity and representation in image retrieval systems, dataset collection, and image generation. For all of these applications, a collection of meaningful and inclusive skin tone annotations is key.
Last year, in a step toward more inclusive computer vision systems, Google’s Responsible AI and Human-Centered Technology team in Research partnered with Dr. Ellis Monk to openly release the Monk Skin Tone (MST) Scale, a skin tone scale that captures a broad spectrum of skin tones. In comparison to an industry standard scale like the Fitzpatrick Skin-Type Scale designed for dermatological use, the MST offers a more inclusive representation across the range of skin tones and was designed for a broad range of applications, including computer vision.
Today we’re announcing the Monk Skin Tone Examples (MST-E) dataset to help practitioners understand the MST scale and train their human annotators. This dataset has been made publicly available to enable practitioners everywhere to create more consistent, inclusive, and meaningful skin tone annotations. Along with this dataset, we’re providing a set of recommendations, noted below, around the MST scale and MST-E dataset so we can all create products that work well for all skin tones.
Since we launched the MST, we’ve been using it to improve Google’s computer vision systems to make equitable image tools for everyone and to improve representation of skin tone in Search. Computer vision researchers and practitioners outside of Google, like the curators of MetaAI’s Casual Conversations dataset, are recognizing the value of MST annotations to provide additional insight into diversity and representation in datasets. Incorporation into widely available datasets like these are essential to give everyone the ability to ensure they are building more inclusive computer vision technologies and can test the quality of their systems and products across a wide range of skin tones.
Our team has continued to conduct research to understand how we can continue to advance our understanding of skin tone in computer vision. One of our core areas of focus has been skin tone annotation, the process by which human annotators are asked to review images of people and select the best representation of their skin tone. MST annotations enable a better understanding of the inclusiveness and representativeness of datasets across a wide range of skin tones, thus enabling researchers and practitioners to evaluate quality and fairness of their datasets and models. To better understand the effectiveness of MST annotations, we’ve asked ourselves the following questions:
- How do people think about skin tone across geographic locations?
- What does global consensus of skin tone look like?
- How do we effectively annotate skin tone for use in inclusive machine learning (ML)?
The MST-E dataset
The MST-E dataset contains 1,515 images and 31 videos of 19 subjects spanning the 10 point MST scale, where the subjects and images were sourced through TONL, a stock photography company focusing on diversity. The 19 subjects include individuals of different ethnicities and gender identities to help human annotators decouple the concept of skin tone from race. The primary goal of this dataset is to enable practitioners to train their human annotators and test for consistent skin tone annotations across various environment capture conditions.
 |
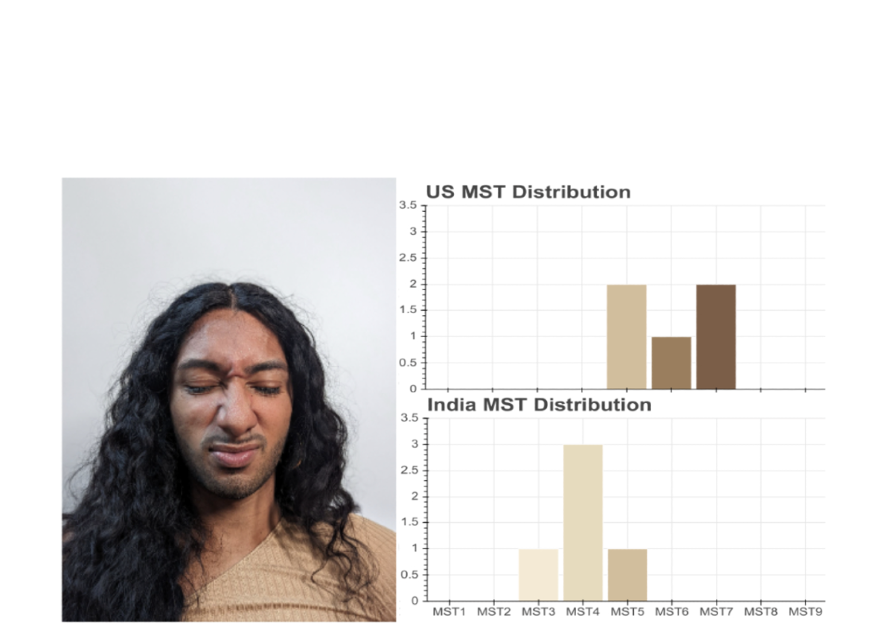
| The MST-E image set contains 1,515 images and 31 videos featuring 19 models taken under various lighting conditions and facial expressions. Images by TONL. Copyright TONL.CO 2022 ALL RIGHTS RESERVED. Used with permission. |
All images of a subject were collected in a single day to reduce variation of skin tone due to seasonal or other temporal effects. Each subject was photographed in various poses, facial expressions, and lighting conditions. In addition, Dr. Monk annotated each subject with a skin tone label and then selected a “golden” image for each subject that best represents their skin tone. In our research we compare annotations made by human annotators to those made by Dr. Monk, an academic expert in social perception and inequality.
Terms of use
Each model selected as a subject provided consent for their images and videos to be released. TONL has given permission for these images to be released as part of MST-E and used for research or human-annotator-training purposes only. The images are not to be used to train ML models.
Challenges with forming consensus of MST annotations
Although skin tone is easy for a person to see, it can be challenging to systematically annotate across multiple people due to issues with technology and the complexity of human social perception.
On the technical side, things like the pixelation, lighting conditions of an image, or a person’s monitor settings can affect how skin tone appears on a screen. You might notice this yourself the next time you change the display setting while watching a show. The hue, saturation, and brightness could all affect how skin tone is displayed on a monitor. Despite these challenges, we find that human annotators are able to learn to become invariant to lighting conditions of an image when annotating skin tone.
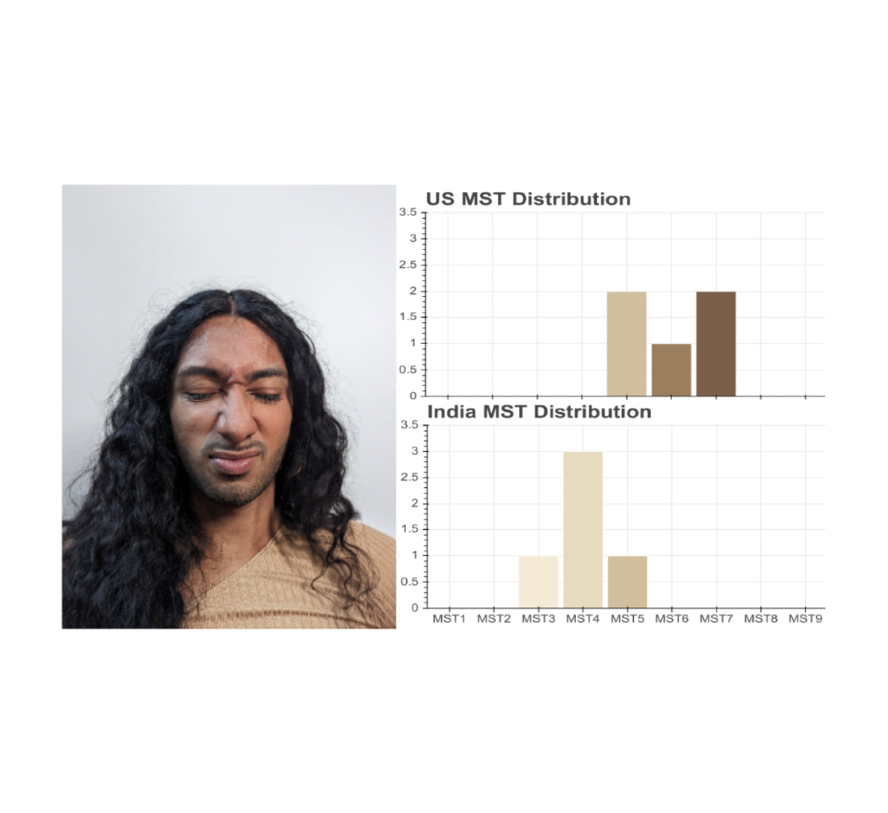
On the social perception side, aspects of a person’s life like their location, culture, and lived experience may affect how they annotate various skin tones. We found some evidence for this when we asked photographers in the United States and photographers in India to annotate the same image. The photographers in the United States viewed this person as somewhere between MST-5 & MST-7. However, the photographers in India viewed this person as somewhere between MST-3 & MST-5.
 |
| The distribution of Monk Skin Tone Scale annotations for this image from a sample of 5 photographers in the U.S. and 5 photographers in India. |
Continuing this exploration, we asked trained annotators from five different geographical regions (India, Philippines, Brazil, Hungary, and Ghana) to annotate skin tone on the MST scale. Within each market each image had 5 annotators who were drawn from a broader pool of annotators in that region. For example, we could have 20 annotators in a market, and select 5 to review a particular image.
With these annotations we found two important details. First, annotators within a region had similar levels of agreement on a single image. Second, annotations between regions were, on average, significantly different from each other. (p<0.05). This suggests that people from the same geographic region may have a similar mental model of skin tone, but this mental model is not universal.
However, even with these regional differences, we also find that the consensus between all five regions falls close to the MST values supplied by Dr. Monk. This suggests that a geographically diverse group of annotators can get close to the MST value annotated by an MST expert. In addition, after training, we find no significant difference between annotations on well-lit images, versus poorly-lit images, suggesting that annotators can become invariant to different lighting conditions in an image — a non-trivial task for ML models.
The MST-E dataset allows researchers to study annotator behavior across curated subsets controlling for potential confounders. We observed similar regional variation when annotating much larger datasets with many more subjects.
Skin Tone annotation recommendations
Our research includes four major findings. First, annotators within a similar geographical region have a consistent and shared mental model of skin tone. Second, these mental models differ across different geographical regions. Third, the MST annotation consensus from a geographically diverse set of annotators aligns with the annotations provided by an expert in social perception and inequality. And fourth, annotators can learn to become invariant to lighting conditions when annotating MST.
Given our research findings, there are a few recommendations for skin tone annotation when using the MST.
- Having a geographically diverse set of annotators is important to gain accurate, or close to ground truth, estimates of skin tone.
- Train human annotators using the MST-E dataset, which spans the entire MST spectrum and contains images in a variety of lighting conditions. This will help annotators become invariant to lighting conditions and appreciate the nuance and differences between the MST points.
- Given the wide range of annotations we suggest having at least two annotators in at least five different geographical regions (10 ratings per image).
Skin tone annotation, like other subjective annotation tasks, is difficult but possible. These types of annotations allow for a more nuanced understanding of model performance, and ultimately help us all to create products that work well for every person across the broad and diverse spectrum of skin tones.
Acknowledgements
We wish to thank our colleagues across Google working on fairness and inclusion in computer vision for their contributions to this work, especially Marco Andreetto, Parker Barnes, Ken Burke, Benoit Corda, Tulsee Doshi, Courtney Heldreth, Rachel Hornung, David Madras, Ellis Monk, Shrikanth Narayanan, Utsav Prabhu, Susanna Ricco, Sagar Savla, Alex Siegman, Komal Singh, Biao Wang, and Auriel Wright. We also would like to thank Annie Jean-Baptiste, Florian Koenigsberger, Marc Repnyek, Maura O’Brien, and Dominique Mungin and the rest of the team who help supervise, fund, and coordinate our data collection.
[ad_2]
Source link