[ad_1]
It’s an incredibly exciting time to be a scientist. With the amazing advances in machine learning (ML) and quantum computing, we now have powerful new tools that enable us to act on our curiosity, collaborate in new ways, and radically accelerate progress toward breakthrough scientific discoveries.
Since joining Google Research eight years ago, I’ve had the privilege of being part of a community of talented researchers fascinated by applying cutting-edge computing to push the boundaries of what is possible in applied science. Our teams are exploring topics across the physical and natural sciences. So, for this year’s blog post I want to focus on high-impact advances we’ve made recently in the fields of biology and physics, from helping to organize the world’s protein and genomics information to benefit people’s lives to improving our understanding of the nature of the universe with quantum computers. We are inspired by the great potential of this work.
Using machine learning to unlock mysteries in biology
Many of our researchers are fascinated by the extraordinary complexity of biology, from the mysteries of the brain, to the potential of proteins, and to the genome, which encodes the very language of life. We’ve been working alongside scientists from other leading organizations around the world to tackle important challenges in the fields of connectomics, protein function prediction, and genomics, and to make our innovations accessible and useful to the greater scientific community.
Neurobiology
One exciting application of our Google-developed ML methods was to explore how information travels through the neuronal pathways in the brains of zebrafish, which provides insight into how the fish engage in social behavior like swarming. In collaboration with researchers from the Max Planck Institute for Biological Intelligence, we were able to computationally reconstruct a portion of zebrafish brains imaged with 3D electron microscopy — an exciting advance in the use of imaging and computational pipelines to map out the neuronal circuitry in small brains, and another step forward in our long-standing contributions to the field of connectomics.
 |
| Reconstruction of the neural circuitry of a larval zebrafish brain, courtesy of the Max Planck Institute for Biological Intelligence. |
The technical advances necessary for this work will have applications even beyond neuroscience. For example, to address the difficulty of working with such large connectomics datasets, we developed and released TensorStore, an open-source C++ and Python software library designed for storage and manipulation of n-dimensional data. We look forward to seeing the ways it is used in other fields for the storage of large datasets.
We’re also using ML to shed light on how human brains perform remarkable feats like language by comparing human language processing and autoregressive deep language models (DLMs). For this study, a collaboration with colleagues at Princeton University and New York University Grossman School of Medicine, participants listened to a 30-minute podcast while their brain activity was recorded using electrocorticography. The recordings suggested that the human brain and DLMs share computational principles for processing language, including continuous next-word prediction, reliance on contextual embeddings, and calculation of post-onset surprise based on word match (we can measure how surprised the human brain is by the word, and correlate that surprise signal with how well the word is predicted by the DLM). These results provide new insights into language processing in the human brain, and suggest that DLMs can be used to reveal valuable insights about the neural basis of language.
Biochemistry
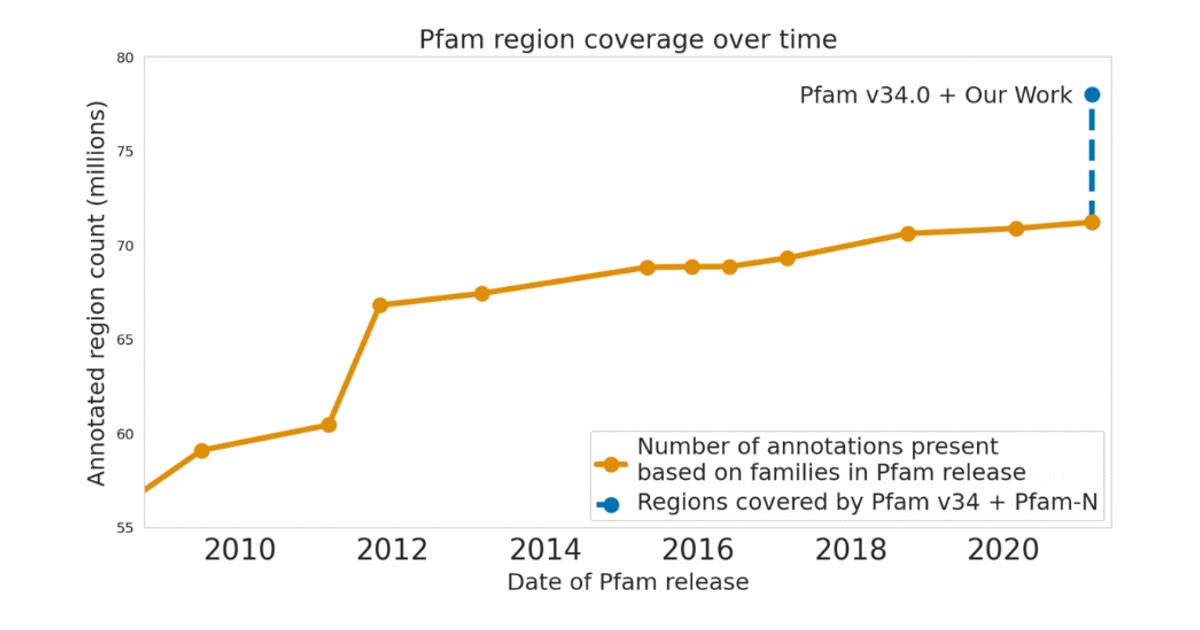
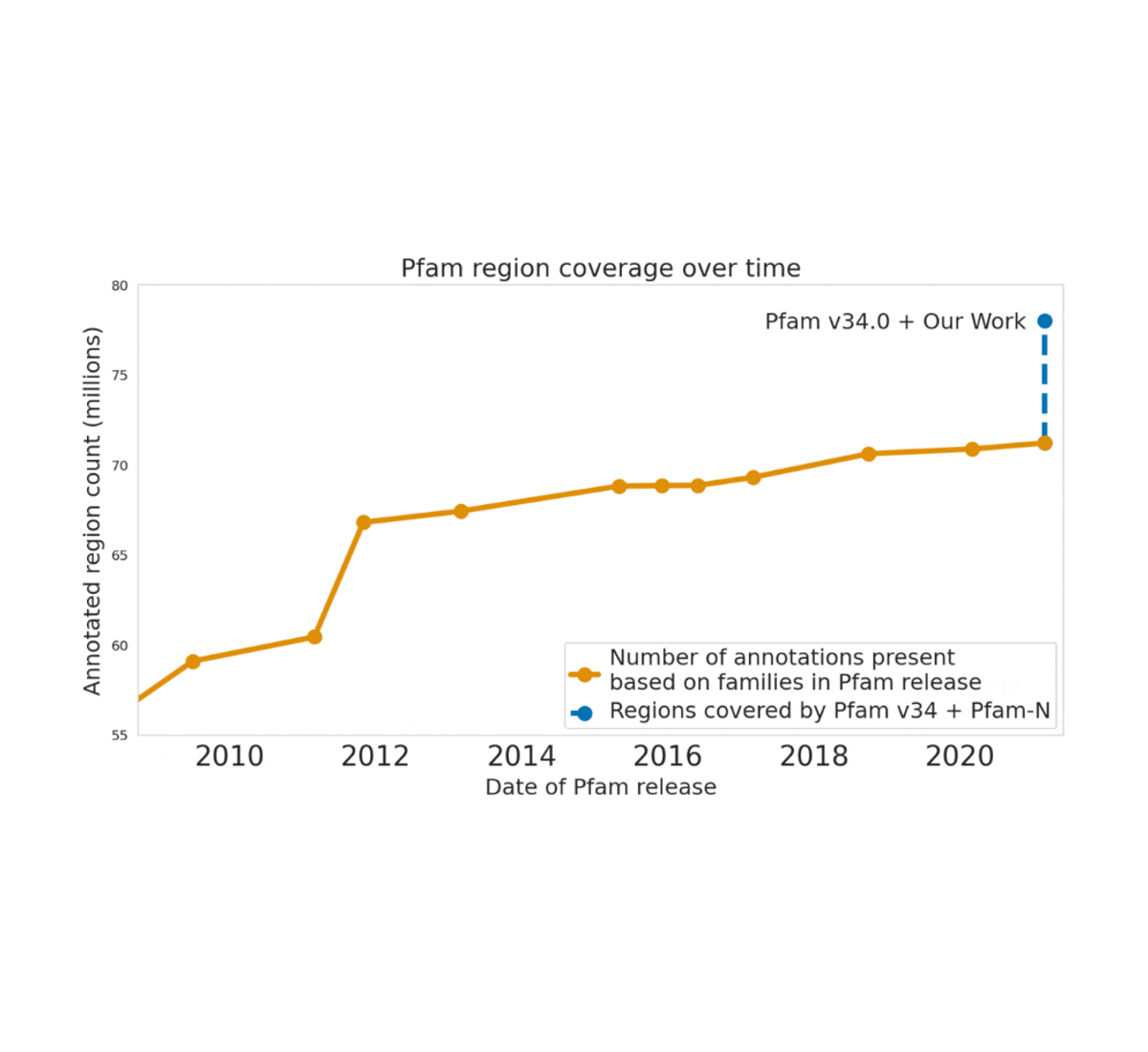
ML has also allowed us to make significant advances in understanding biological sequences. In 2022, we leveraged recent advances in deep learning to accurately predict protein function from raw amino acid sequences. We also worked in close collaboration with the European Molecular Biology Laboratory’s European Bioinformatics Institute (EMBL-EBI) to carefully assess model performance and add hundreds of millions of functional annotations to the public protein databases UniProt, Pfam/InterPro, and MGnify. Human annotation of protein databases can be a laborious and slow process and our ML methods enabled a giant leap forward — for example, increasing the number of Pfam annotations by a larger number than all other efforts during the past decade combined. The millions of scientists worldwide who access these databases each year can now use our annotations for their research.
 |
| Google Research contributions to Pfam exceed in size all expansion efforts made to the database over the last decade. |
Although the first draft of the human genome was released in 2003, it was incomplete and had many gaps due to technical limitations in the sequencing technologies. In 2022 we celebrated the remarkable achievements of the Telomere-2-Telomere (T2T) Consortium in resolving these previously unavailable regions — including five full chromosome arms and nearly 200 million base pairs of novel DNA sequences — which are interesting and important for questions of human biology, evolution, and disease. Our open source genomics variant caller, DeepVariant, was one of the tools used by the T2T Consortium to prepare their release of a complete 3.055 billion base pair sequence of a human genome. The T2T Consortium is also using our newer open source method DeepConsensus, which provides on-device error correction for Pacific Biosciences long-read sequencing instruments, in their latest research toward comprehensive pan-genome resources that can represent the breadth of human genetic diversity.
Using quantum computing for new physics discoveries
When it comes to making scientific discoveries, quantum computing is still in its infancy, but has a lot of potential. We’re exploring ways of advancing the capabilities of quantum computing so that it can become a tool for scientific discovery and breakthroughs. In collaboration with physicists from around the world, we are also starting to use our existing quantum computers to create interesting new experiments in physics.
As an example of such experiments, consider the problem where a sensor measures something, and a computer then processes the data from the sensor. Traditionally, this means the sensor’s data is processed as classical information on our computers. Instead, one idea in quantum computing is to directly process quantum data from sensors. Feeding data from quantum sensors directly to quantum algorithms without going through classical measurements may provide a large advantage. In a recent Science paper written in collaboration with researchers from multiple universities, we show that quantum computing can extract information from exponentially fewer experiments than classical computing, as long as the quantum computer is coupled directly to the quantum sensors and is running a learning algorithm. This “quantum machine learning” can yield an exponential advantage in dataset size, even with today’s noisy intermediate-scale quantum computers. Because experimental data is often the limiting factor in scientific discovery, quantum ML has the potential to unlock the vast power of quantum computers for scientists. Even better, the insights from this work are also applicable to learning on the output of quantum computations, such as the output of quantum simulations that may otherwise be difficult to extract.
Even without quantum ML, a powerful application of quantum computers is to experimentally explore quantum systems that would be otherwise impossible to observe or simulate. In 2022, the Quantum AI team used this approach to observe the first experimental evidence of multiple microwave photons in a bound state using superconducting qubits. Photons typically do not interact with one another, and require an additional element of non-linearity to cause them to interact. The results of our quantum computer simulations of these interactions surprised us — we thought the existence of these bound states relied on fragile conditions, but instead we found that they were robust even to relatively strong perturbations that we applied.
 |
| Occupation probability versus discrete time step for n-photon bound states. We observe that the majority of the photons (darker colors) remain bound together. |
Given the initial successes we have had in applying quantum computing to make physics breakthroughs, we are hopeful about the possibility of this technology to enable future groundbreaking discoveries that could have as significant a societal impact as the creation of transistors or GPS. The future of quantum computing as a scientific tool is exciting!
Acknowledgements
I would like to thank everyone who worked hard on the advances described in this post, including the Google Applied Sciences, Quantum AI, Genomics and Brain teams and their collaborators across Google Research and externally. Finally, I would like to thank the many Googlers who provided feedback in the writing of this post, including Lizzie Dorfman, Erica Brand, Elise Kleeman, Abe Asfaw, Viren Jain, Lucy Colwell, Andrew Carroll, Ariel Goldstein and Charina Chou.
Google Research, 2022 & beyond
This was the seventh blog post in the “Google Research, 2022 & Beyond” series. Other posts in this series are listed in the table below:
| * Articles will be linked as they are released. |
[ad_2]
Source link