[ad_1]
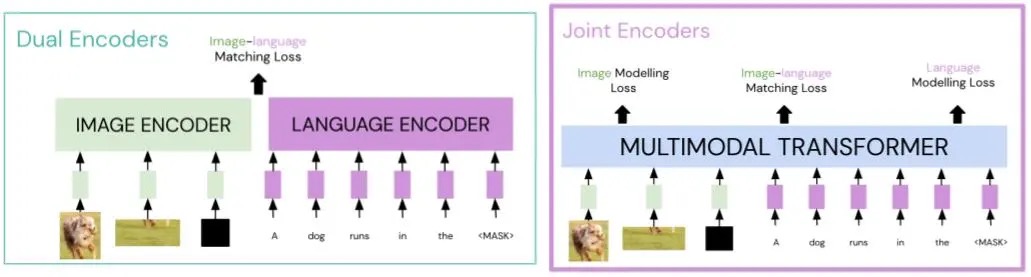
The ability to ground language to vision is a fundamental aspect of real-world AI systems; it is useful across a range of tasks (e.g., visual question answering) and applications (e.g., generating descriptions for visually impaired). Multimodal models (pre-trained on image-language pairs) aim to address this grounding problem. A recent family of models, multimodal transformers (e.g., Lu et al., 2019; Chen et al., 2020; Tan and Bansal, 2019; Li et al., 2020), have achieved state-of-the-art performance in a range of multimodal benchmarks, suggesting that the joint-encoder transformer architecture is better suited for capturing the alignment between image-language pairs than previous approaches (such as dual encoders).

In particular, compared to the dual-encoder architecture where there is no cross-talk between the modalities, multimodal transformers (joint encoders) are more sample efficient. In the plot below, we see that, when tested on zero-shot image retrieval, an existing multimodal transformer (UNITER) performs similar to a large-scale dual encoder (CLIP) which is trained on 100 times more data.

In this work, we examine what aspects of multimodal transformers – attention, losses, and pretraining data – are important in their success at multimodal pretraining. We find that Multimodal attention, where both language and image transformers attend to each other, is crucial for these models’ success. Models with other types of attention (even with more depth or parameters) fail to achieve comparable results to shallower and smaller models with multimodal attention. Moreover, comparable results can be achieved without the image (masked region modelling) loss originally proposed for multimodal transformers. This suggests that our current models are not tapping into the useful signal in the image modality, presumably because of the image loss formulation.
We also study different properties of multimodal datasets such as their size and the degree to which the language describes its corresponding image (noisiness). We find that a dataset’s size does not always predict multimodal transformers’ performance; its noise level and language similarity to the evaluation task are both important contributing factors. These suggest curating less noisy image–text datasets to be important despite the current trend of harvesting noisy datasets from the web.
Overall, our analysis shows that multimodal transformers are stronger than dual encoder architecture (given the same amount of pretraining data), mainly due to the cross-talk through multimodal attention. However, there are still many open problems when designing multimodal models, including better losses for the image modality and robustness to dataset noise.
[ad_2]
Source link








