[ad_1]
During purely curious exploration, the JACO arm discovers how to pick up cubes, moves them around the workspace and even explores whether they can be balanced on their edges.
Curious exploration enables OP3 to walk upright, balance on one foot, sit down and even catch itself safely when leaping backwards – all without a specific target task to optimise for.
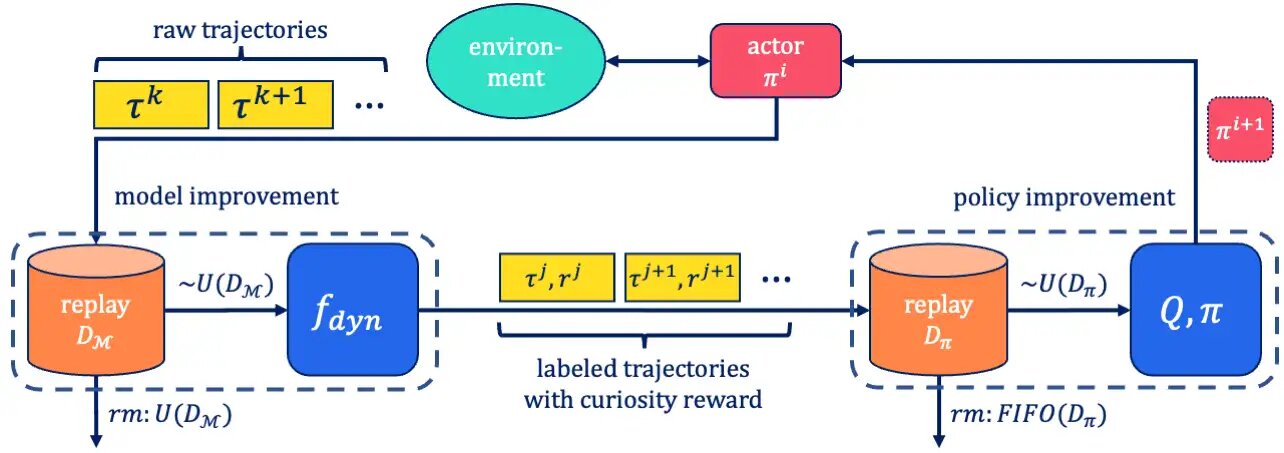
Intrinsic motivation [1, 2] can be a powerful concept to endow an agent with a mechanism to continuously explore its environment in the absence of task information. One common way to implement intrinsic motivation is via curiosity learning [3, 4]. With this method, a predictive model about the environment’s response to an agent’s actions is trained alongside the agent’s policy. This model can also be called a world model. When an action is taken, the world model makes a prediction about the agent’s next observation. This prediction is then compared to the true observation made by the agent. Crucially, the reward given to the agent for taking this action is scaled by the error it made when predicting the next observation. This way, the agent is rewarded for taking actions whose outcomes are not yet well predictable. Simultaneously, the world model is updated to better predict the outcome of said action.
This mechanism has been applied successfully in on-policy settings, e.g. to beat 2D computer games in an unsupervised way [4] or to train a general policy which is easily adaptable to concrete downstream tasks [5]. However, we believe that the true strength of curiosity learning lies in the diverse behaviour which emerges during the curious exploration process: As the curiosity objective changes, so does the resulting behaviour of the agent thereby discovering many complex policies which could be utilised later on, if they were retained and not overwritten.
In this paper, we make two contributions to study curiosity learning and harness its emergent behaviour: First, we introduce SelMo, an off-policy realisation of a self-motivated, curiosity-based method for exploration. We show that using SelMo, meaningful and diverse behaviour emerges solely based on the optimisation of the curiosity objective in simulated manipulation and locomotion domains. Second, we propose to extend the focus in the application of curiosity learning towards the identification and retention of emerging intermediate behaviours. We support this conjecture with an experiment which reloads self-discovered behaviours as pretrained, auxiliary skills in a hierarchical reinforcement learning setup.

We run SelMo in two simulated continuous control robotic domains: On a 6-DoF JACO arm with a three-fingered gripper and on a 20-DoF humanoid robot, the OP3. The respective platforms present challenging learning environments for object manipulation and locomotion, respectively. While only optimising for curiosity, we observe that complex human-interpretable behaviour emerges over the course of the training runs. For instance, JACO learns to pick up and move cubes without any supervision or the OP3 learns to balance on a single foot or sit down safely without falling over.
.jpg)
.jpg)
However, the impressive behaviours observed during curious exploration have one crucial drawback: They are not persistent as they keep changing with the curiosity reward function. As the agent keeps repeating a certain behaviour, e.g. JACO lifting the red cube, the curiosity rewards accumulated by this policy are diminishing. Consequently, this leads to the learning of a modified policy which acquires higher curiosity rewards again, e.g. moving the cube outside the workspace or even attending to the other cube. But this new behaviour overwrites the old one. However, we believe that retaining the emergent behaviours from curious exploration equips the agent with a valuable skill set to learn new tasks more quickly. In order to investigate this conjecture, we set up an experiment to probe the utility of the self-discovered skills.
.jpg)
We treat randomly sampled snapshots from different phases of the curious exploration as auxiliary skills in a modular learning framework [7] and measure how quickly a new target skill can be learned by using those auxiliaries. In the case of the JACO arm, we set the target task to be “lift the red cube” and use five randomly sampled self-discovered behaviours as auxiliaries. We compare the learning of this downstream task to an SAC-X baseline [8] which uses a curriculum of reward functions to reward reaching and moving the red cube which ultimately facilitates to learn lifting as well. We find that even this simple setup for skill-reuse already speeds up the learning progress of the downstream task commensurate with a hand designed reward curriculum. The results suggest that the automatic identification and retention of useful emerging behaviour from curious exploration is a fruitful avenue of future investigation in unsupervised reinforcement learning.
[ad_2]
Source link








