[ad_1]
In our recent paper we explore how multi-agent deep reinforcement learning can serve as a model of complex social interactions, like the formation of social norms. This new class of models could provide a path to create richer, more detailed simulations of the world.
Humans are an ultra social species. Relative to other mammals we benefit more from cooperation but we are also more dependent on it, and face greater cooperation challenges. Today, humanity faces numerous cooperation challenges including preventing conflict over resources, ensuring everyone can access clean air and drinking water, eliminating extreme poverty, and combating climate change. Many of the cooperation problems we face are difficult to resolve because they involve complex webs of social and biophysical interactions called social-ecological systems. However, humans can collectively learn to overcome the cooperation challenges we face. We accomplish this by an ever evolving culture, including norms and institutions which organize our interactions with the environment and with one another.
However, norms and institutions sometimes fail to resolve cooperation challenges. For example, individuals may over-exploit resources like forests and fisheries thereby causing them to collapse. In such cases, policy-makers may write laws to change institutional rules or develop other interventions to try to change norms in hopes of bringing about a positive change. But policy interventions do not always work as intended. This is because real-world social-ecological systems are considerably more complex than the models we typically use to try to predict the effects of candidate policies.
Models based on game theory are often applied to the study of cultural evolution. In most of these models, the key interactions that agents have with one another are expressed in a ‘payoff matrix’. In a game with two participants and two actions A and B, a payoff matrix defines the value of the four possible outcomes: (1) we both choose A, (2) we both choose B, (3) I choose A while you choose B and (4) I choose B while you choose A. The most famous example is the ‘Prisoner’s Dilemma’, in which the actions are interpreted as “cooperate” and “defect”. Rational agents who act according to their own myopic self-interest are doomed to defect in the Prisoner’s Dilemma even though the better outcome of mutual cooperation is available.
Game-theoretic models have been very widely applied. Researchers in diverse fields have used them to study a wide range of different phenomena, including economies and the evolution of human culture. However, game theory is not a neutral tool, rather it is a deeply opinionated modeling language. It imposes a strict requirement that everything must ultimately cash out in terms of the payoff matrix (or equivalent representation). This means that the modeler has to know, or be willing to assume, everything about how the effects of individual actions combine to generate incentives. This is sometimes appropriate, and the game theoretic approach has had many notable successes such as in modeling the behavior of oligopolistic firms and cold war era international relations. However, game theory’s major weakness as a modeling language is exposed in situations where the modeler does not fully understand how the choices of individuals combine to generate payoffs. Unfortunately this tends to be the case with social-ecological systems because their social and ecological parts interact in complex ways that we do not fully understand.
The work we present here is one example within a research program that attempts to establish an alternative modeling framework, different from game theory, to use in the study of social-ecological systems. Our approach may be seen formally as a variety of agent-based modeling. However, its distinguishing feature is the incorporation of algorithmic elements from artificial intelligence, especially multi-agent deep reinforcement learning.
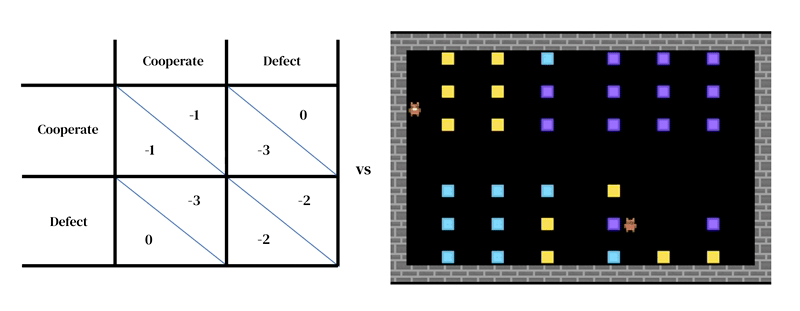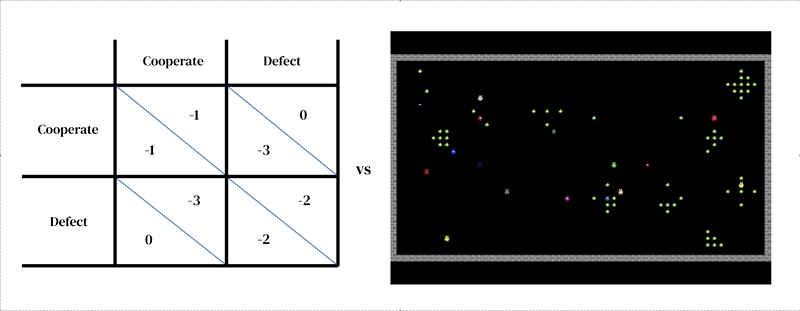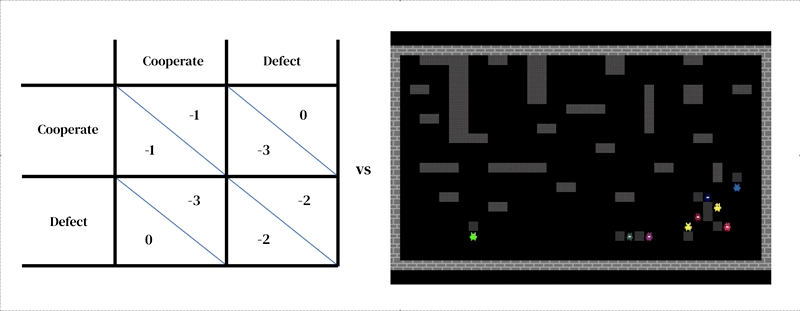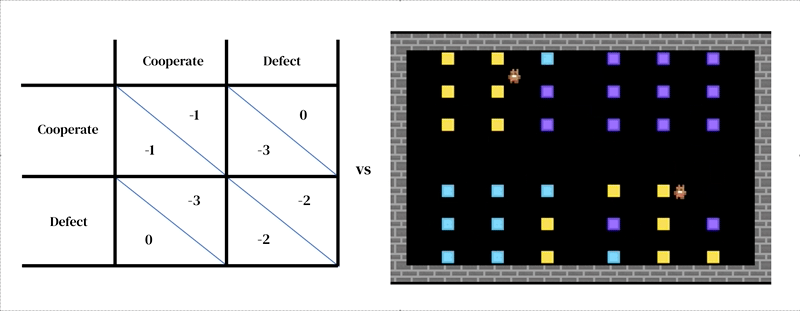
The core idea of this approach is that every model consists of two interlocking parts: (1) a rich, dynamical model of the environment and (2) a model of individual decision-making.
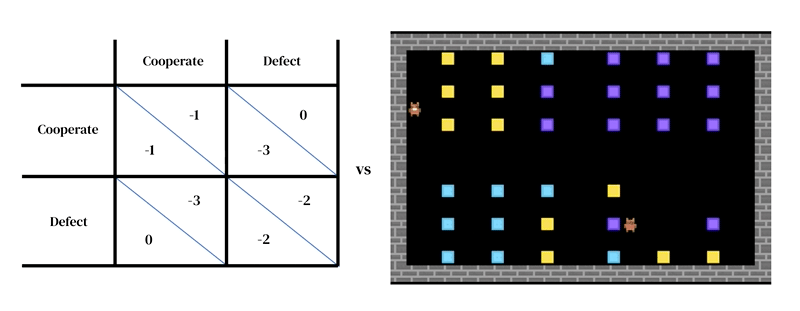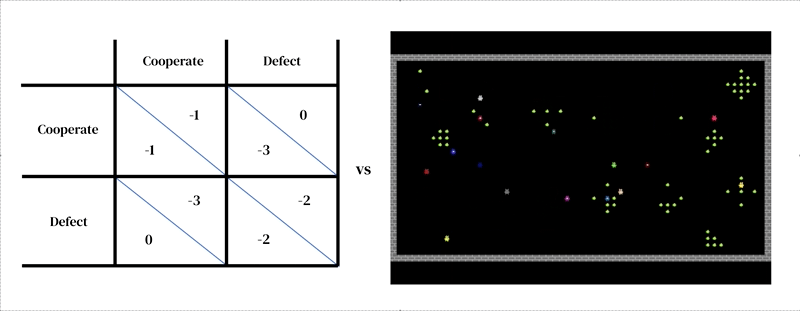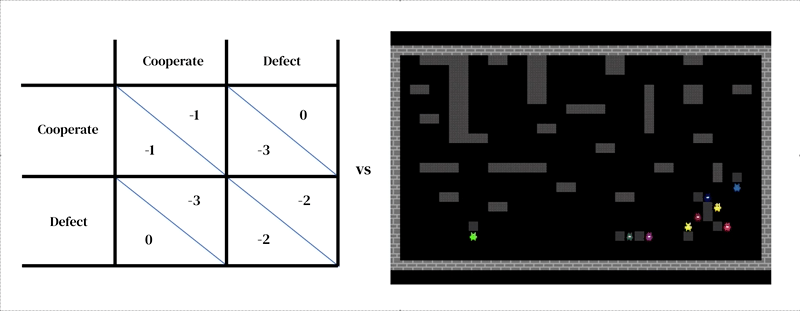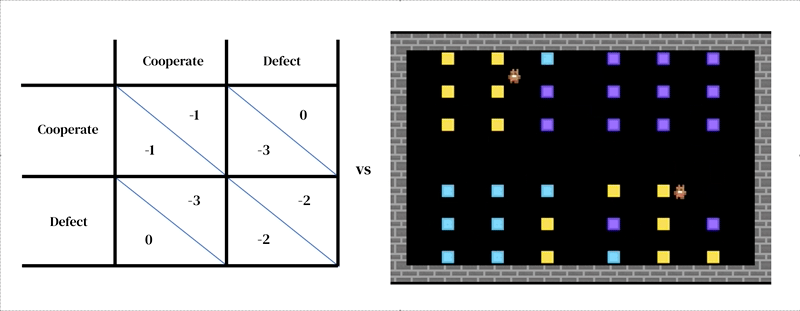
The first takes the form of a researcher-designed simulator: an interactive program that takes in a current environment state and agent actions, and outputs the next environment state as well as the observations of all agents and their instantaneous rewards. The model of individual decision-making is likewise conditioned on environment state. It is an agent that learns from its past experience, performing a form of trial-and-error. An agent interacts with an environment by taking in observations and outputting actions. Each agent selects actions according to its behavioral policy, a mapping from observations to actions. Agents learn by changing their policy to improve it along any desired dimension, typically to obtain more reward. The policy is stored in a neural network. Agents learn ‘from scratch’, from their own experience, how the world works and what they can do to earn more rewards. They accomplish this by tuning their network weights in such a way that the pixels they receive as observations are gradually transformed into competent actions. Several learning agents can inhabit the same environment as one another. In this case the agents become interdependent because their actions affect one another.
Like other agent-based modeling approaches, multi-agent deep reinforcement learning makes it easy to specify models that cross levels of analysis that would be hard to treat with game theory. For instance, actions may be far closer to low-level motor primitives (e.g. ‘walk forward’; ‘turn right’) than the high-level strategic decisions of game theory (e.g. ‘cooperate’). This is an important feature needed to capture situations where agents must practice to learn effectively how to implement their strategic choices. For instance in one study, agents learned to cooperate by taking turns cleaning a river. This solution was only possible because the environment had spatial and temporal dimensions in which agents have great freedom in how they structure their behavior towards one another. Interestingly, while the environment allowed for many different solutions (such as territoriality), agents converged on the same turn-taking solution as human players.
In our latest study, we applied this type of model to an open question in research on cultural evolution: how to explain the existence of spurious and arbitrary social norms that appear not to have immediate material consequences for their violation beyond those imposed socially. For instance, in some societies men are expected to wear trousers not skirts; in many there are words or hand gestures that should not be used in polite company; and in most there are rules about how one styles one’s hair or what one wears on one’s head. We call these social norms ‘silly rules’. Importantly, in our framework, enforcing and complying with social norms both have to be learned. Having a social environment that includes a ‘silly rule’ means that agents have more opportunities to learn about enforcing norms in general. This additional practice then allows them to enforce the important rules more effectively. Overall, the ‘silly rule’ can be beneficial for the population – a surprising result. This result is only possible because our simulation focuses on learning: enforcing and complying with rules are complex skills that need training to develop.
Part of why we find this result on silly rules so exciting is that it demonstrates the utility of multi-agent deep reinforcement learning in modeling cultural evolution. Culture contributes to the success or failure of policy interventions for socio-ecological systems. For instance, strengthening social norms around recycling is part of the solution to some environmental problems. Following this trajectory, richer simulations could lead to a deeper understanding of how to design interventions for social-ecological systems. If simulations become realistic enough, it may even be possible to test the impact of interventions, e.g. aiming to design a tax code that fosters productivity and fairness.
This approach provides researchers with tools to specify detailed models of phenomena that interest them. Of course, like all research methodologies it should be expected to come with its own strengths and weaknesses. We hope to discover more about when this style of modeling can be fruitfully applied in the future. While there are no panaceas for modeling, we think there are compelling reasons to look to multi-agent deep reinforcement learning when constructing models of social phenomena, especially when they involve learning.
[ad_2]
Source link








