[ad_1]
Reward is the driving force for reinforcement learning (RL) agents. Given its central role in RL, reward is often assumed to be suitably general in its expressivity, as summarized by Sutton and Littman’s reward hypothesis:
“…all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward).”
– SUTTON (2004), LITTMAN (2017)
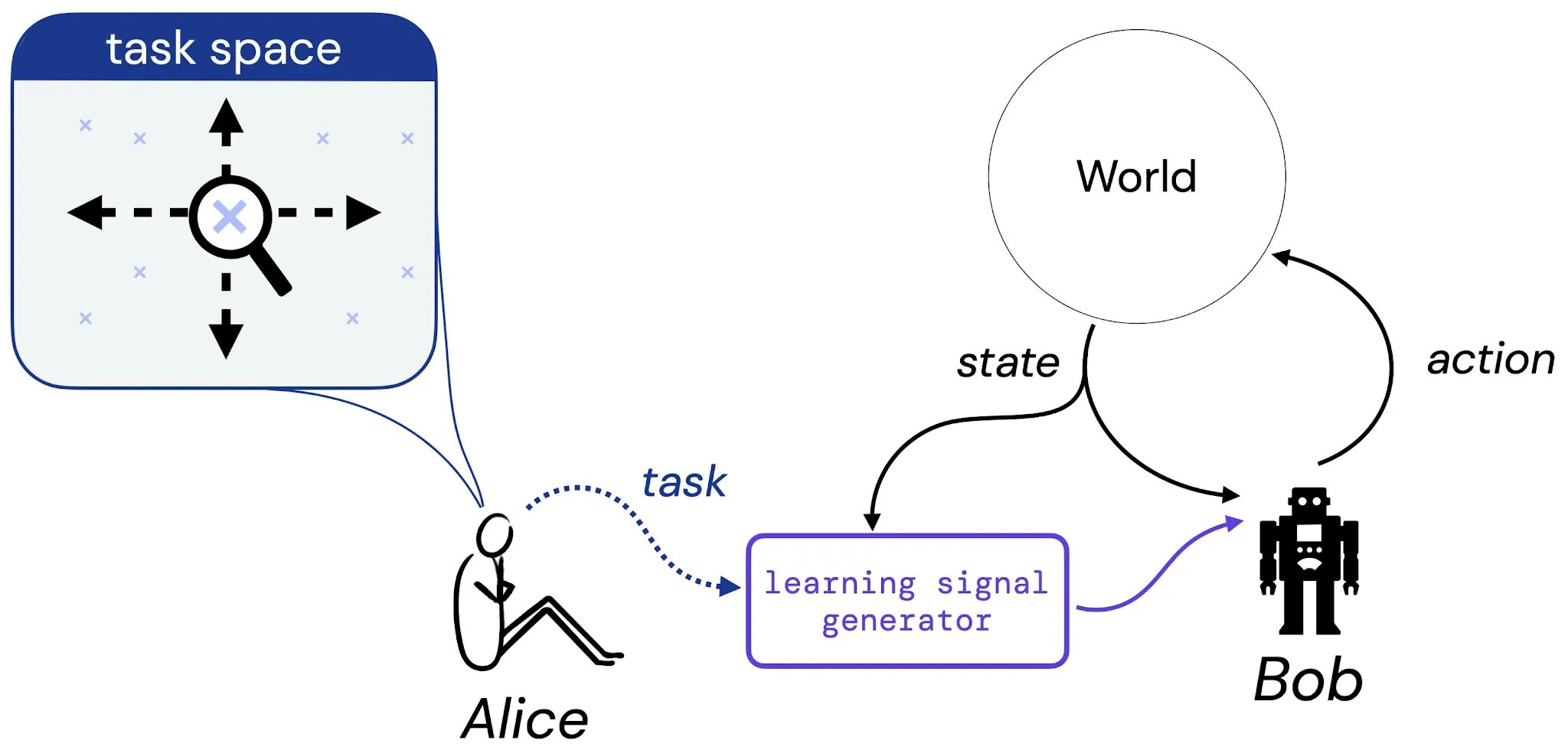
In our work, we take first steps toward a systematic study of this hypothesis. To do so, we consider the following thought experiment involving Alice, a designer, and Bob, a learning agent:
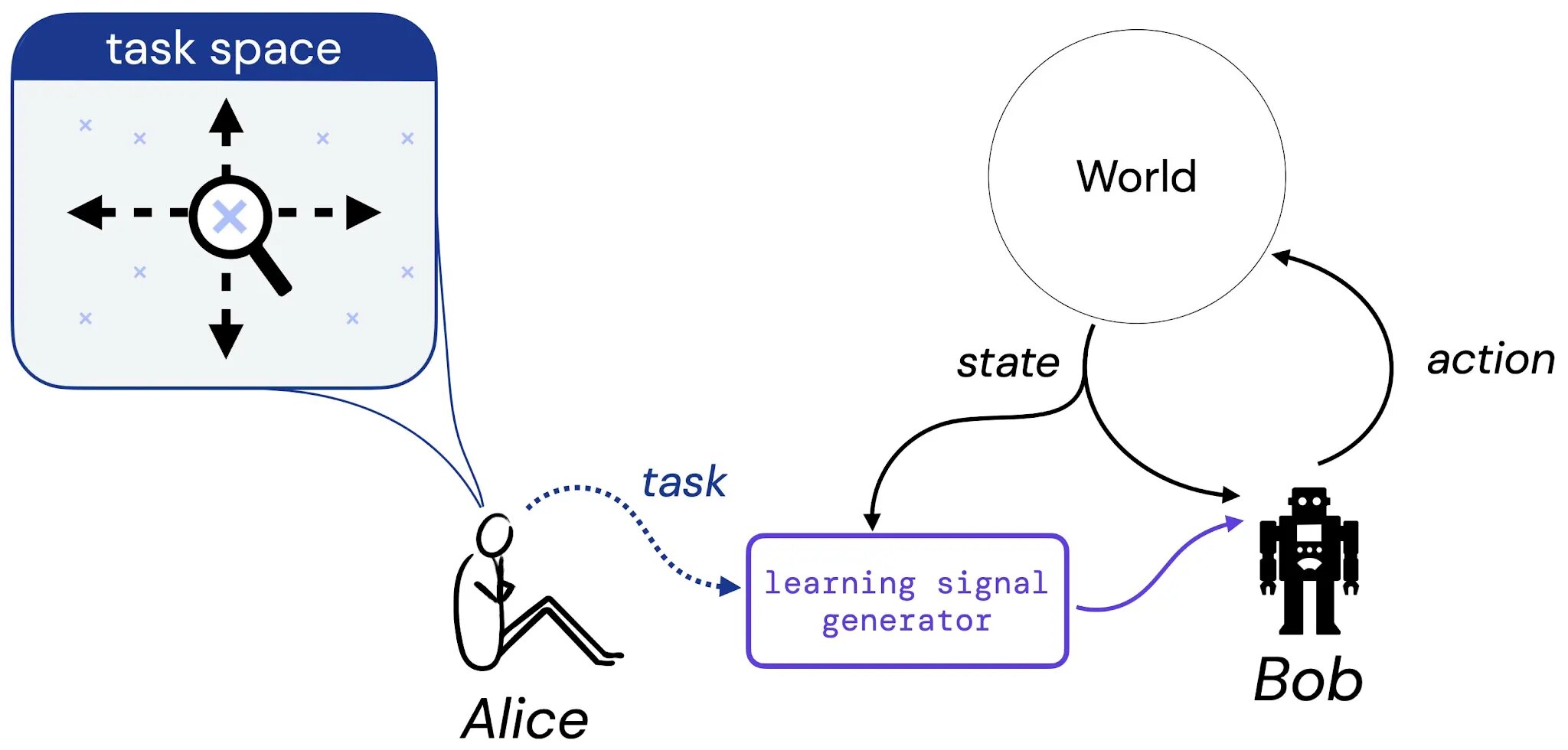
We suppose that Alice thinks of a task she might like Bob to learn to solve – this task could be in the form a a natural language description (“balance this pole”), an imagined state of affairs (“reach any of the winning configurations of a chess board”), or something more traditional like a reward or value function. Then, we imagine Alice translates her choice of task into some generator that will provide learning signal (such as reward) to Bob (a learning agent), who will learn from this signal throughout his lifetime. We then ground our study of the reward hypothesis by addressing the following question: given Alice’s choice of task, is there always a reward function that can convey this task to Bob?
What is a task?
To make our study of this question concrete, we first restrict focus to three kinds of task. In particular, we introduce three task types that we believe capture sensible kinds of tasks: 1) A set of acceptable policies (SOAP), 2) A policy order (PO), and 3) A trajectory order (TO). These three forms of tasks represent concrete instances of the kinds of task we might want an agent to learn to solve.
.jpg)
We then study whether reward is capable of capturing each of these task types in finite environments. Crucially, we only focus attention on Markov reward functions; for instance, given a state space that is sufficient to form a task such as (x,y) pairs in a grid world, is there a reward function that only depends on this same state space that can capture the task?
First Main Result
Our first main result shows that for each of the three task types, there are environment-task pairs for which there is no Markov reward function that can capture the task. One example of such a pair is the “go all the way around the grid clockwise or counterclockwise” task in a typical grid world:
.jpg)
This task is naturally captured by a SOAP that consists of two acceptable policies: the “clockwise” policy (in blue) and the “counterclockwise” policy (in purple). For a Markov reward function to express this task, it would need to make these two policies strictly higher in value than all other deterministic policies. However, there is no such Markov reward function: the optimality of a single “move clockwise” action will depend on whether the agent was already moving in that direction in the past. Since the reward function must be Markov, it cannot convey this kind of information. Similar examples demonstrate that Markov reward cannot capture every policy order and trajectory order, too.
Second Main Result
Given that some tasks can be captured and some cannot, we next explore whether there is an efficient procedure for determining whether a given task can be captured by reward in a given environment. Further, if there is a reward function that captures the given task, we would ideally like to be able to output such a reward function. Our second result is a positive result which says that for any finite environment-task pair, there is a procedure that can 1) decide whether the task can be captured by Markov reward in the given environment, and 2) outputs the desired reward function that exactly conveys the task, when such a function exists.
This work establishes initial pathways toward understanding the scope of the reward hypothesis, but there is much still to be done to generalize these results beyond finite environments, Markov rewards, and simple notions of “task” and “expressivity”. We hope this work provides new conceptual perspectives on reward and its place in reinforcement learning.
[ad_2]
Source link








