
[ad_1]
In our recent paper, we explore how populations of deep reinforcement learning (deep RL) agents can learn microeconomic behaviours, such as production, consumption, and trading of goods. We find that artificial agents learn to make economically rational decisions about production, consumption, and prices, and react appropriately to supply and demand changes. The population converges to local prices that reflect the nearby abundance of resources, and some agents learn to transport goods between these areas to “buy low and sell high”. This work advances the broader multi-agent reinforcement learning research agenda by introducing new social challenges for agents to learn how to solve.
Insofar as the goal of multi-agent reinforcement learning research is to eventually produce agents that work across the full range and complexity of human social intelligence, the set of domains so far considered has been woefully incomplete. It is still missing crucial domains where human intelligence excels, and humans spend significant amounts of time and energy. The subject matter of economics is one such domain. Our goal in this work is to establish environments based on the themes of trading and negotiation for use by researchers in multi-agent reinforcement learning.
Economics uses agent-based models to simulate how economies behave. These agent-based models often build in economic assumptions about how agents should act. In this work, we present a multi-agent simulated world where agents can learn economic behaviours from scratch, in ways familiar to any Microeconomics 101 student: decisions about production, consumption, and prices. But our agents also must make other choices that follow from a more physically embodied way of thinking. They must navigate a physical environment, find trees to pick fruits, and partners to trade them with. Recent advances in deep RL techniques now make it possible to create agents that can learn these behaviours on their own, without requiring a programmer to encode domain knowledge.
Our environment, called Fruit Market, is a multiplayer environment where agents produce and consume two types of fruit: apples and bananas. Each agent is skilled at producing one type of fruit, but has a preference for the other – if the agents can learn to barter and exchange goods, both parties would be better off.

In our experiments, we demonstrate that current deep RL agents can learn to trade, and their behaviours in response to supply and demand shifts align with what microeconomic theory predicts. We then build on this work to present scenarios that would be very difficult to solve using analytical models, but which are straightforward for our deep RL agents. For example, in environments where each type of fruit grows in a different area, we observe the emergence of different price regions related to the local abundance of fruit, as well as the subsequent learning of arbitrage behaviour by some agents, who begin to specialise in transporting fruit between these regions.
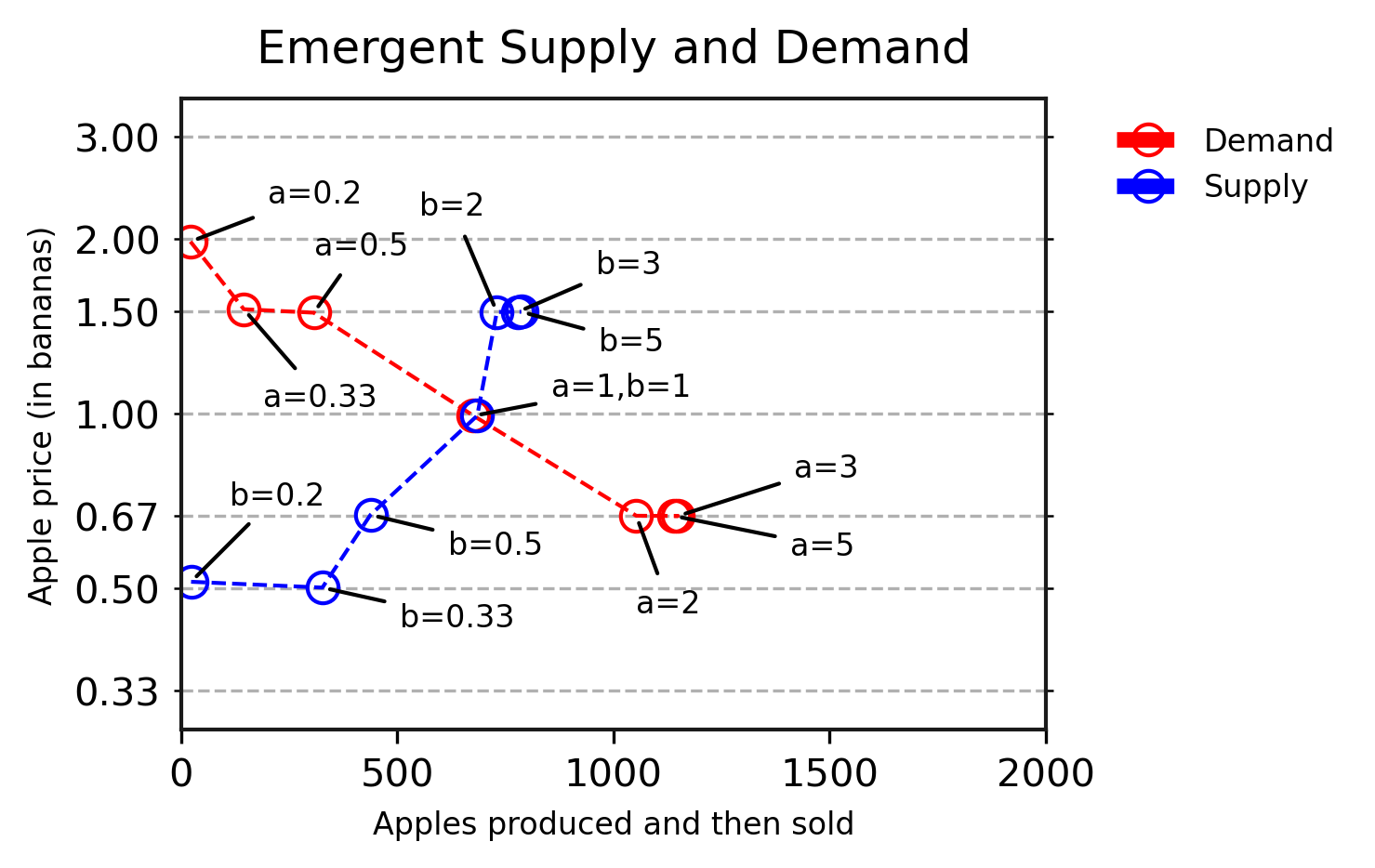
The field of agent-based computational economics uses similar simulations for economics research. In this work, we also demonstrate that state-of-the-art deep RL techniques can flexibly learn to act in these environments from their own experience, without needing to have economic knowledge built in. This highlights the reinforcement learning community’s recent progress in multi-agent RL and deep RL, and demonstrates the potential of multi-agent techniques as tools to advance simulated economics research.
As a path to artificial general intelligence (AGI), multi-agent reinforcement learning research should encompass all critical domains of social intelligence. However, until now it hasn’t incorporated traditional economic phenomena such as trade, bargaining, specialisation, consumption, and production. This paper fills this gap and provides a platform for further research. To aid future research in this area, the Fruit Market environment will be included in the next release of the Melting Pot suite of environments.
[ad_2]
Source link








