[ad_1]
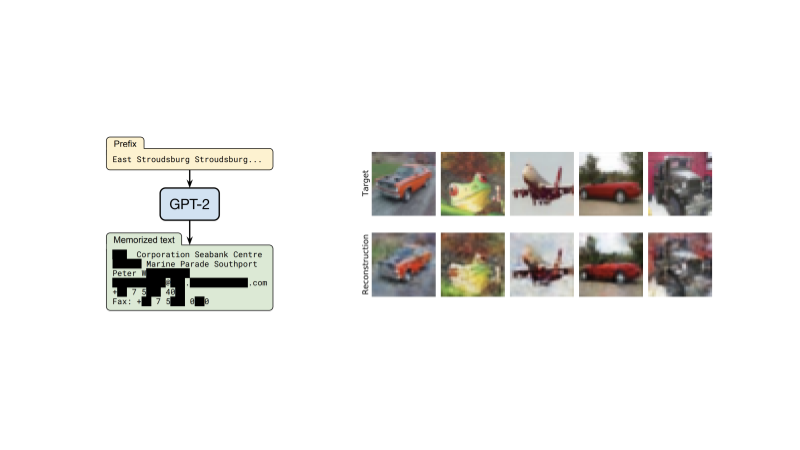
A recent DeepMind paper on the ethical and social risks of language models identified large language models leaking sensitive information about their training data as a potential risk that organisations working on these models have the responsibility to address. Another recent paper shows that similar privacy risks can also arise in standard image classification models: a fingerprint of each individual training image can be found embedded in the model parameters, and malicious parties could exploit such fingerprints to reconstruct the training data from the model.
Privacy-enhancing technologies like differential privacy (DP) can be deployed at training time to mitigate these risks, but they often incur significant reduction in model performance. In this work, we make substantial progress towards unlocking high-accuracy training of image classification models under differential privacy.

Differential privacy was proposed as a mathematical framework to capture the requirement of protecting individual records in the course of statistical data analysis (including the training of machine learning models). DP algorithms protect individuals from any inferences about the features that make them unique (including complete or partial reconstruction) by injecting carefully calibrated noise during the computation of the desired statistic or model. Using DP algorithms provides robust and rigorous privacy guarantees both in theory and in practice, and has become a de-facto gold standard adopted by a number of public and private organisations.
The most popular DP algorithm for deep learning is differentially private stochastic gradient descent (DP-SGD), a modification of standard SGD obtained by clipping gradients of individual examples and adding enough noise to mask the contribution of any individual to each model update:
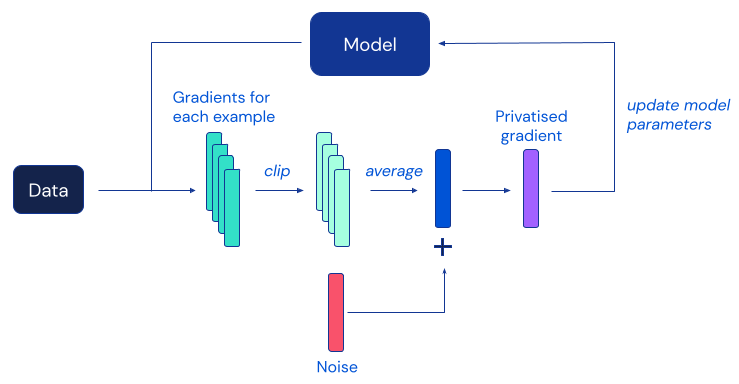
Unfortunately, prior works have found that in practice, the privacy protection provided by DP-SGD often comes at the cost of significantly less accurate models, which presents a major obstacle to the widespread adoption of differential privacy in the machine learning community. According to empirical evidence from prior works, this utility degradation in DP-SGD becomes more severe on larger neural network models – including the ones regularly used to achieve the best performance on challenging image classification benchmarks.
Our work investigates this phenomenon and proposes a series of simple modifications to both the training procedure and model architecture, yielding a significant improvement on the accuracy of DP training on standard image classification benchmarks. The most striking observation coming out of our research is that DP-SGD can be used to efficiently train much deeper models than previously thought, as long as one ensures the model’s gradients are well-behaved. We believe the substantial jump in performance achieved by our research has the potential to unlock practical applications of image classification models trained with formal privacy guarantees.
The figure below summarises two of our main results: an ~10% improvement on CIFAR-10 compared to previous work when privately training without additional data, and a top-1 accuracy of 86.7% on ImageNet when privately fine-tuning a model pre-trained on a different dataset, almost closing the gap with the best non-private performance.

These results are achieved at 𝜺=8, a standard setting for calibrating the strength of the protection offered by differential privacy in machine learning applications. We refer to the paper for a discussion of this parameter, as well as additional experimental results at other values of 𝜺 and also on other datasets. Together with the paper, we are also open-sourcing our implementation to enable other researchers to verify our findings and build on them. We hope this contribution will help others interested in making practical DP training a reality.
Download our JAX implementation on GitHub.
[ad_2]
Source link








