[ad_1]
Recent advances have expanded the applicability of language models (LM) to downstream tasks. On one hand, existing language models that are properly prompted, via chain-of-thought, demonstrate emergent capabilities that carry out self-conditioned reasoning traces to derive answers from questions, excelling at various arithmetic, commonsense, and symbolic reasoning tasks. However, with chain-of-thought prompting, a model is not grounded in the external world and uses its own internal representations to generate reasoning traces, limiting its ability to reactively explore and reason or update its knowledge. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g., text games, web navigation, embodied tasks, robotics), with a focus on mapping text contexts to text actions via the language model’s internal knowledge. However, they do not reason abstractly about high-level goals or maintain a working memory to support acting over long horizons.
In “ReAct: Synergizing Reasoning and Acting in Language Models”, we propose a general paradigm that combines reasoning and acting advances to enable language models to solve various language reasoning and decision making tasks. We demonstrate that the Reason+Act (ReAct) paradigm systematically outperforms reasoning and acting only paradigms, when prompting bigger language models and fine-tuning smaller language models. The tight integration of reasoning and acting also presents human-aligned task-solving trajectories that improve interpretability, diagnosability, and controllability..
Model Overview
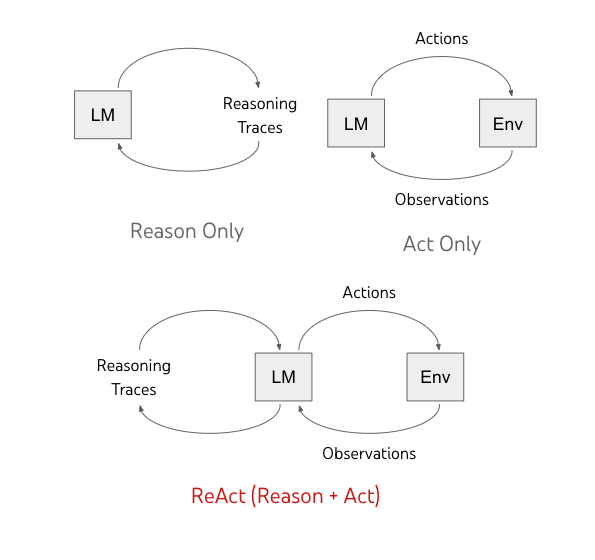
ReAct enables language models to generate both verbal reasoning traces and text actions in an interleaved manner. While actions lead to observation feedback from an external environment (“Env” in the figure below), reasoning traces do not affect the external environment. Instead, they affect the internal state of the model by reasoning over the context and updating it with useful information to support future reasoning and acting.
 |
| Previous methods prompt language models (LM) to either generate self-conditioned reasoning traces or task-specific actions. We propose ReAct, a new paradigm that combines reasoning and acting advances in language models. |
ReAct Prompting
We focus on the setup where a frozen language model, PaLM-540B, is prompted with few-shot in-context examples to generate both domain-specific actions (e.g., “search” in question answering, and “go to” in room navigation), and free-form language reasoning traces (e.g., “Now I need to find a cup, and put it on the table”) for task solving.
For tasks where reasoning is of primary importance, we alternate the generation of reasoning traces and actions so that the task-solving trajectory consists of multiple reasoning-action-observation steps. In contrast, for decision making tasks that potentially involve a large number of actions, reasoning traces only need to appear sparsely in the most relevant positions of a trajectory, so we write prompts with sparse reasoning and let the language model decide the asynchronous occurrence of reasoning traces and actions for itself.
As shown below, there are various types of useful reasoning traces, e.g., decomposing task goals to create action plans, injecting commonsense knowledge relevant to task solving, extracting important parts from observations, tracking task progress while maintaining plan execution, handling exceptions by adjusting action plans, and so on.
The synergy between reasoning and acting allows the model to perform dynamic reasoning to create, maintain, and adjust high-level plans for acting (reason to act), while also interacting with the external environments (e.g., Wikipedia) to incorporate additional information into reasoning (act to reason).
ReAct Fine-tuning
We also explore fine-tuning smaller language models using ReAct-format trajectories. To reduce the need for large-scale human annotation, we use the ReAct prompted PaLM-540B model to generate trajectories, and use trajectories with task success to fine-tune smaller language models (PaLM-8/62B).
 |
| Comparison of four prompting methods, (a) Standard, (b) Chain of thought (CoT, Reason Only), (c) Act-only, and (d) ReAct, solving a HotpotQA question. In-context examples are omitted, and only the task trajectory is shown. ReAct is able to retrieve information to support reasoning, while also using reasoning to target what to retrieve next, demonstrating a synergy of reasoning and acting. |
Results
We conduct empirical evaluations of ReAct and state-of-the-art baselines across four different benchmarks: question answering (HotPotQA), fact verification (Fever), text-based game (ALFWorld), and web page navigation (WebShop). For HotPotQA and Fever, with access to a Wikipedia API with which the model can interact, ReAct outperforms vanilla action generation models while being competitive with chain of thought reasoning (CoT) performance. The approach with the best results is a combination of ReAct and CoT that uses both internal knowledge and externally obtained information during reasoning.
| HotpotQA (exact match, 6-shot) | FEVER (accuracy, 3-shot) | |
| Standard | 28.7 | 57.1 |
| Reason-only (CoT) | 29.4 | 56.3 |
| Act-only | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| Best ReAct + CoT Method | 35.1 | 64.6 |
| Supervised SoTA | 67.5 (using ~140k samples) | 89.5 (using ~90k samples) |
| PaLM-540B prompting results on HotpotQA and Fever. |
On ALFWorld and WebShop, ReAct with both one-shot and two-shot prompting outperforms imitation and reinforcement learning methods trained with ~105 task instances, with an absolute improvement of 34% and 10% in success rates, respectively, over existing baselines.
| AlfWorld (2-shot) | WebShop (1-shot) | |
| Act-only | 45 | 30.1 |
| ReAct | 71 | 40 |
| Imitation Learning Baselines | 37 (using ~100k samples) | 29.1 (using ~90k samples) |
| PaLM-540B prompting task success rate results on AlfWorld and WebShop. |
 |
| Scaling results for prompting and fine-tuning on HotPotQA with ReAct and different baselines. ReAct consistently achieves best fine-tuning performances. |
 |
 |
| A comparison of the ReAct (top) and CoT (bottom) reasoning trajectories on an example from Fever (observation for ReAct is omitted to reduce space). In this case ReAct provided the right answer, and it can be seen that the reasoning trajectory of ReAct is more grounded on facts and knowledge, in contrast to CoT’s hallucination behavior. |
We also explore human-in-the-loop interactions with ReAct by allowing a human inspector to edit ReAct’s reasoning traces. We demonstrate that by simply replacing a hallucinating sentence with inspector hints, ReAct can change its behavior to align with inspector edits and successfully complete a task. Solving tasks becomes significantly easier when using ReAct as it only requires the manual editing of a few thoughts, which enables new forms of human-machine collaboration.
 |
| A human-in-the-loop behavior correction example with ReAct on AlfWorld. (a) ReAct trajectory fails due to a hallucinating reasoning trace (Act 17). (b) A human inspector edits two reasoning traces (Act 17, 23), ReAct then produces desirable reasoning traces and actions to complete the task. |
Conclusion
We present ReAct, a simple yet effective method for synergizing reasoning and acting in language models. Through various experiments that focus on multi-hop question-answering, fact checking, and interactive decision-making tasks, we show that ReAct leads to superior performance with interpretable decision traces.
ReAct demonstrates the feasibility of jointly modeling thought, actions and feedback from the environment within a language model, making it a versatile agent that is capable of solving tasks that require interactions with the environment. We plan to further extend this line of research and leverage the strong potential of the language model for tackling broader embodied tasks, via approaches like massive multitask training and coupling ReAct with equally strong reward models.
Acknowledgements
We would like to thank Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran and Karthik Narasimhan for their great contribution in this work. We would also like to thank Google’s Brain team and the Princeton NLP Group for their joint support and feedback, including project scoping, advising and insightful discussions.
[ad_2]
Source link