[ad_1]
Over the last few years, autoregressive Transformers have brought a steady stream of breakthroughs in generative modeling. These models generate each element of a sample – the pixels of an image, the characters of a text (typically in “token” chunks), the samples of an audio waveform, and so on – by predicting one element after the other. When predicting the next element, the model can look back at those that were created earlier.
However, each of a Transformer’s layers grows more expensive as more elements are used as input, and practitioners can only afford to train deep Transformers on sequences no more than about 2,048 elements in length. And so, most Transformer-based models ignore all elements beyond the most recent past (around 1,500 words or 1/6 of a small image) when making a prediction.
In contrast, our recently developed Perceiver models give excellent results on a variety of real-world tasks with up to around 100,000 elements. Perceivers use cross-attention to encode inputs into a latent space, decoupling the input’s compute requirements from model depth. Perceivers also spend a fixed cost, regardless of input size, at nearly every layer.
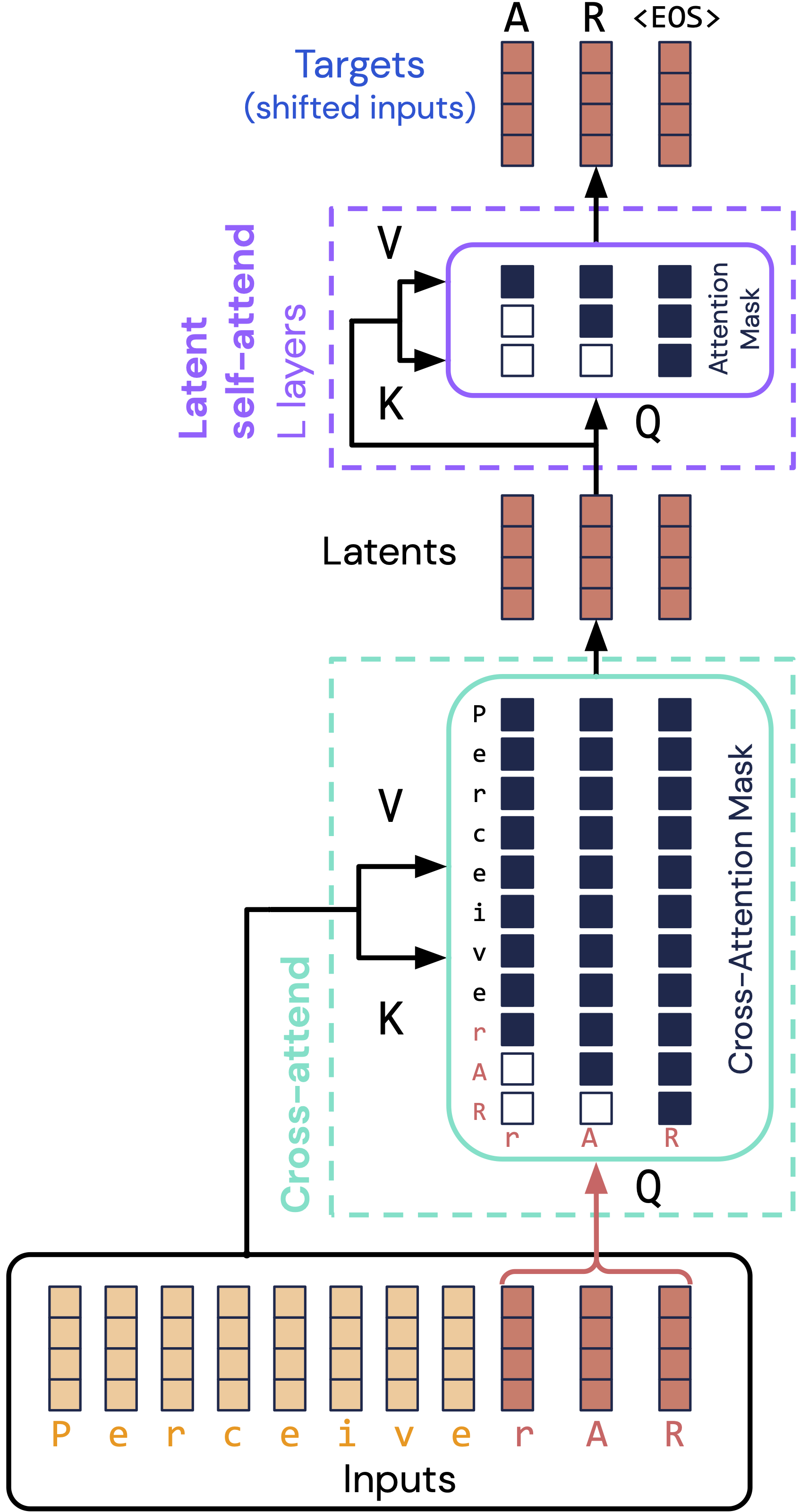
While latent-space encoding handles all elements in a single pass, autoregressive generation assumes processing happens one element at a time. To address this problem, Perceiver AR proposes a simple solution: align the latents one by one with the final elements of the input, and carefully mask the input so latents see only earlier elements.

The result is an architecture (shown above) that attends to as much as 50x longer inputs as standard Transformers, while deploying as widely (and essentially as easily) as standard decoder-only Transformers.

Perceiver AR scales considerably better with size than both standard Transformers and Transformer-XL models at a range of sequence lengths in real terms. This property allows us to build very effective long-context models. For example, we find that a 60-layer Perceiver AR with context length 8192 outperforms a 42-layer Transformer-XL on a book-length generation task, while running faster in real wall-clock terms.
On standard, long-context image (ImageNet 64×64), language (PG-19), and music (MAESTRO) generation benchmarks, Perceiver AR produces state-of-the-art results. Increasing input context by decoupling input size from compute budget leads to several intriguing results:
- Compute budget can be adapted at eval time, allowing us to spend less and smoothly degrade quality or to spend more for improved generation.
- A larger context allows Perceiver AR to outperform Transformer-XL, even when spending the same on compute. We find that greater context leads to improved model performance even at affordable scale (~1B parameters).
- Perceiver AR’s sample quality exhibits much less sensitivity to the order in which it generates elements. This makes Perceiver AR easy to apply to settings that don’t have a natural left-to-right ordering, such as data like images, with structure that spans more than one dimension.
Using a dataset of piano music, we trained Perceiver AR to generate new pieces of music from scratch. Because each new note is predicted based on the full sequence of notes that came before, Perceiver AR is able to produce pieces with a high level of melodic, harmonic, and rhythmic coherence:
Learn more about using Perceiver AR:
- Download the JAX code for training Perceiver AR on Github
- Read our paper on arXiv
- Check out our spotlight presentation at ICML 2022
See the Google Magenta blog post with more music!
[ad_2]
Source link








