
[ad_1]
Using human and animal motions to teach robots to dribble a ball, and simulated humanoid characters to carry boxes and play football

Five years ago, we took on the challenge of teaching a fully articulated humanoid character to traverse obstacle courses. This demonstrated what reinforcement learning (RL) can achieve through trial-and-error but also highlighted two challenges in solving embodied intelligence:
- Reusing previously learned behaviours: A significant amount of data was needed for the agent to “get off the ground”. Without any initial knowledge of what force to apply to each of its joints, the agent started with random body twitching and quickly falling to the ground. This problem could be alleviated by reusing previously learned behaviours.
- Idiosyncratic behaviours: When the agent finally learned to navigate obstacle courses, it did so with unnatural (albeit amusing) movement patterns that would be impractical for applications such as robotics.
Here, we describe a solution to both challenges called neural probabilistic motor primitives (NPMP), involving guided learning with movement patterns derived from humans and animals, and discuss how this approach is used in our Humanoid Football paper, published today in Science Robotics.
We also discuss how this same approach enables humanoid full-body manipulation from vision, such as a humanoid carrying an object, and robotic control in the real-world, such as a robot dribbling a ball.
Distilling data into controllable motor primitives using NPMP
An NPMP is a general-purpose motor control module that translates short-horizon motor intentions to low-level control signals, and it’s trained offline or via RL by imitating motion capture (MoCap) data, recorded with trackers on humans or animals performing motions of interest.

The model has two parts:
- An encoder that takes a future trajectory and compresses it into a motor intention.
- A low-level controller that produces the next action given the current state of the agent and this motor intention.
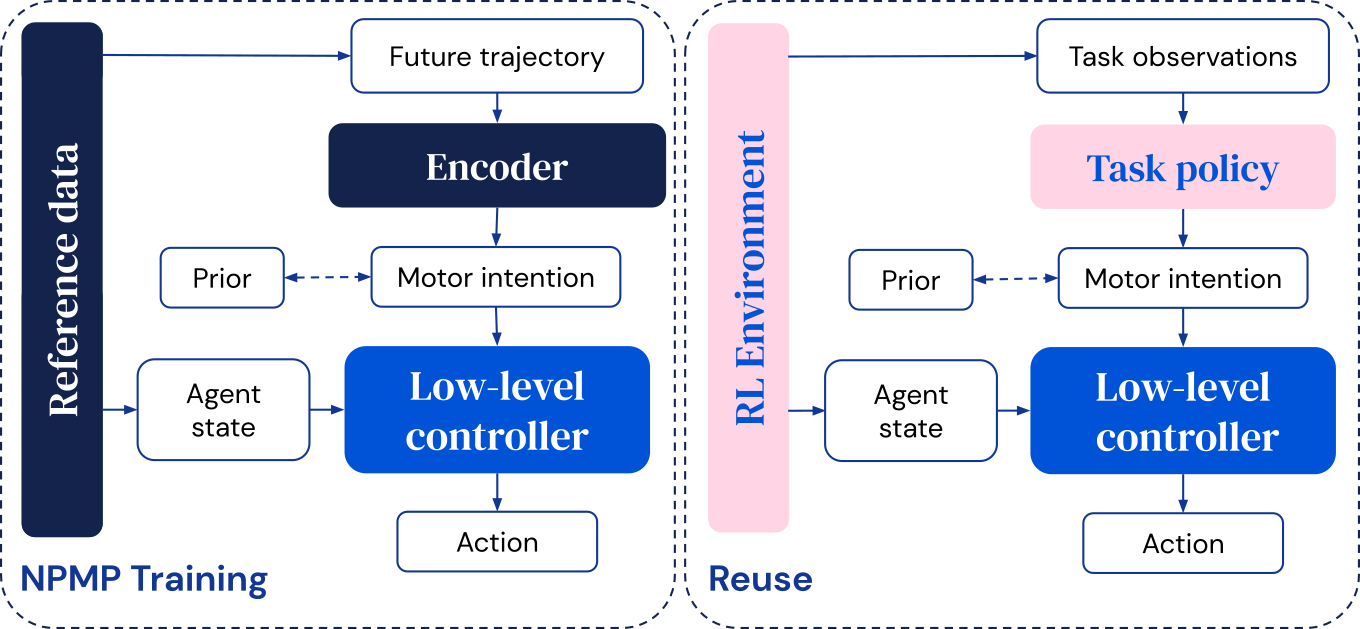
After training, the low-level controller can be reused to learn new tasks, where a high-level controller is optimised to output motor intentions directly. This enables efficient exploration – since coherent behaviours are produced, even with randomly sampled motor intentions – and constrains the final solution.
Emergent team coordination in humanoid football
Football has been a long-standing challenge for embodied intelligence research, requiring individual skills and coordinated team play. In our latest work, we used an NPMP as a prior to guide the learning of movement skills.
The result was a team of players which progressed from learning ball-chasing skills, to finally learning to coordinate. Previously, in a study with simple embodiments, we had shown that coordinated behaviour can emerge in teams competing with each other. The NPMP allowed us to observe a similar effect but in a scenario that required significantly more advanced motor control.


Our agents acquired skills including agile locomotion, passing, and division of labour as demonstrated by a range of statistics, including metrics used in real-world sports analytics. The players exhibit both agile high-frequency motor control and long-term decision-making that involves anticipation of teammates’ behaviours, leading to coordinated team play.

Whole-body manipulation and cognitive tasks using vision
Learning to interact with objects using the arms is another difficult control challenge. The NPMP can also enable this type of whole-body manipulation. With a small amount of MoCap data of interacting with boxes, we’re able to train an agent to carry a box from one location to another, using egocentric vision and with only a sparse reward signal:


Similarly, we can teach the agent to catch and throw balls:
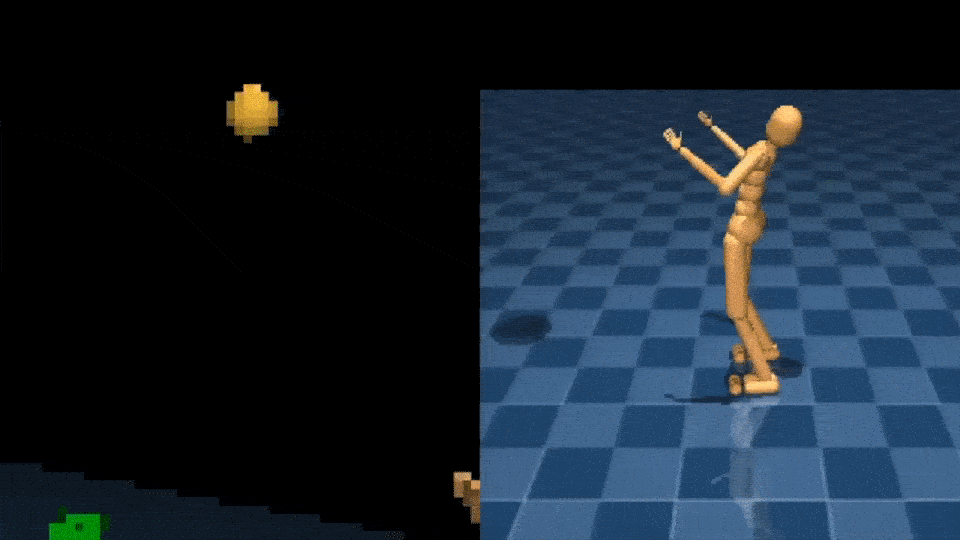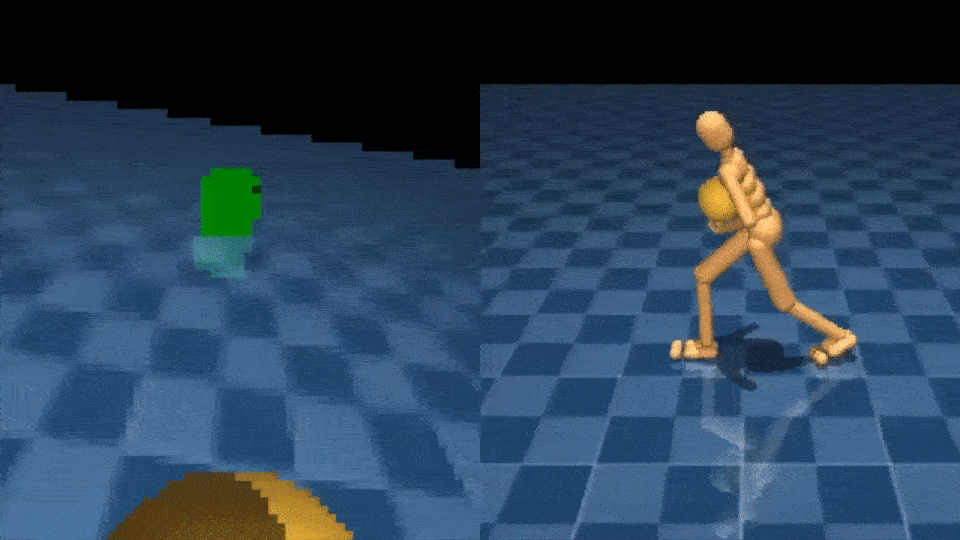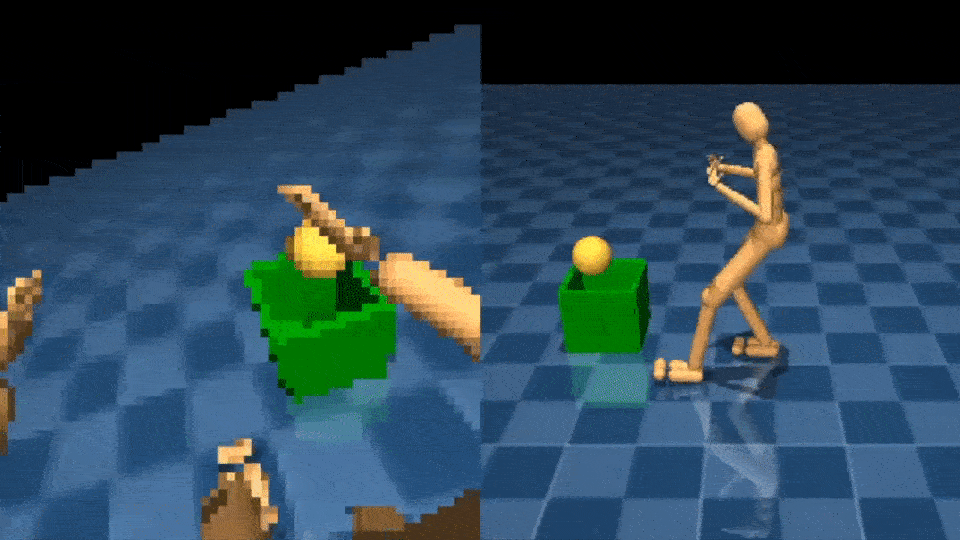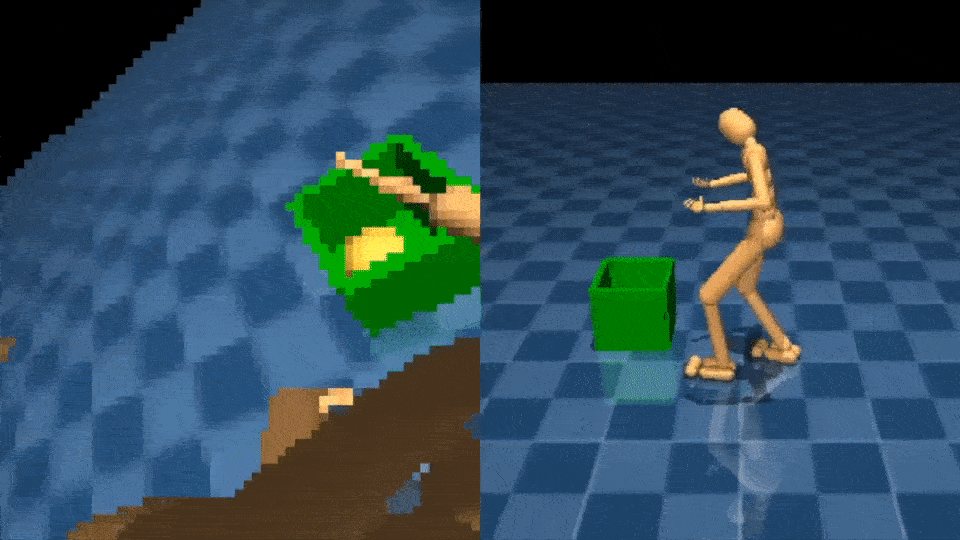
Using NPMP, we can also tackle maze tasks involving locomotion, perception and memory:

Safe and efficient control of real-world robots
The NPMP can also help to control real robots. Having well-regularised behaviour is critical for activities like walking over rough terrain or handling fragile objects. Jittery motions can damage the robot itself or its surroundings, or at least drain its battery. Therefore, significant effort is often invested into designing learning objectives that make a robot do what we want it to while behaving in a safe and efficient manner.
As an alternative, we investigated whether using priors derived from biological motion can give us well-regularised, natural-looking, and reusable movement skills for legged robots, such as walking, running, and turning that are suitable for deploying on real-world robots.
Starting with MoCap data from humans and dogs, we adapted the NPMP approach to train skills and controllers in simulation that can then be deployed on real humanoid (OP3) and quadruped (ANYmal B) robots, respectively. This allowed the robots to be steered around by a user via a joystick or dribble a ball to a target location in a natural-looking and robust way.



Benefits of using neural probabilistic motor primitives
In summary, we’ve used the NPMP skill model to learn complex tasks with humanoid characters in simulation and real-world robots. The NPMP packages low-level movement skills in a reusable fashion, making it easier to learn useful behaviours that would be difficult to discover by unstructured trial and error. Using motion capture as a source of prior information, it biases learning of motor control toward that of naturalistic movements.
The NPMP enables embodied agents to learn more quickly using RL; to learn more naturalistic behaviours; to learn more safe, efficient and stable behaviours suitable for real-world robotics; and to combine full-body motor control with longer horizon cognitive skills, such as teamwork and coordination.
Learn more about our work:
[ad_2]
Source link








