[ad_1]
Today many people have digital access to their medical records, including their doctor’s clinical notes. However, clinical notes are hard to understand because of the specialized language that clinicians use, which contains unfamiliar shorthand and abbreviations. In fact, there are thousands of such abbreviations, many of which are specific to certain medical specialities and locales or can mean multiple things in different contexts. For example, a doctor might write in their clinical notes, “pt referred to pt for lbp“, which is meant to convey the statement: “Patient referred to physical therapy for low back pain.” Coming up with this translation is tough for laypeople and computers because some abbreviations are uncommon in everyday language (e.g., “lbp” means “low back pain”), and even familiar abbreviations, such as “pt” for “patient”, can have alternate meanings, such as “physical therapy.” To disambiguate between multiple meanings, the surrounding context must be considered. It’s no easy task to decipher all the meanings, and prior research suggests that expanding the shorthand and abbreviations can help patients better understand their health, diagnoses, and treatments.
In “Deciphering clinical abbreviations with a privacy protecting machine learning system”, published in Nature Communications, we report our findings on a general method that deciphers clinical abbreviations in a way that is both state-of-the-art and is on-par with board certified physicians in this task. We built the model using only public data on the web that wasn’t associated with any patient (i.e., no potentially sensitive data) and evaluated performance on real, de-identified notes from inpatient and outpatient clinicians from different health systems. To enable the model to generalize from web-data to notes, we created a way to algorithmically re-write large amounts of internet text to look as if it were written by a doctor (called web-scale reverse substitution), and we developed a novel inference method, (called elicitive inference).
 |
| The model input is a string that may or may not contain medical abbreviations. We trained a model to output a corresponding string in which all abbreviations are simultaneously detected and expanded. If the input string does not contain an abbreviation, the model will output the original string. By Rajkomar et al used under CC BY 4.0/ Cropped from original. |
Rewriting Text to Include Medical Abbreviations
Building a system to translate doctors’ notes would usually start with a large, representative dataset of clinical text where all abbreviations are labeled with their meanings. But no such dataset for general use by researchers exists. We therefore sought to develop an automated way to create such a dataset but without the use of any actual patient notes, which might include sensitive data. We also wanted to ensure that models trained on this data would still work well on real clinical notes from multiple hospital sites and types of care, such as both outpatient and inpatient.
To do this, we referenced a dictionary of thousands of clinical abbreviations and their expansions, and found sentences on the web that contained uses of the expansions from this dictionary. We then “rewrote” those sentences by abbreviating each expansion, resulting in web data that looked like it was written by a doctor. For instance, if a website contained the phrase “patients with atrial fibrillation can have chest pain,” we would rewrite this sentence to “pts with af can have cp.” We then used the abbreviated text as input to the model, with the original text serving as the label. This approach provided us with large amounts of data to train our model to perform abbreviation expansion.
The idea of “reverse substituting” the long-forms for their abbreviations was introduced in prior research, but our distributed algorithm allows us to extend the technique to large, web-sized datasets. Our algorithm, called web-scale reverse substitution (WSRS), is designed to ensure that rare terms occur more frequently and common terms are down-sampled across the public web to derive a more balanced dataset. With this data in-hand, we trained a series of large transformer-based language models to expand the web text.
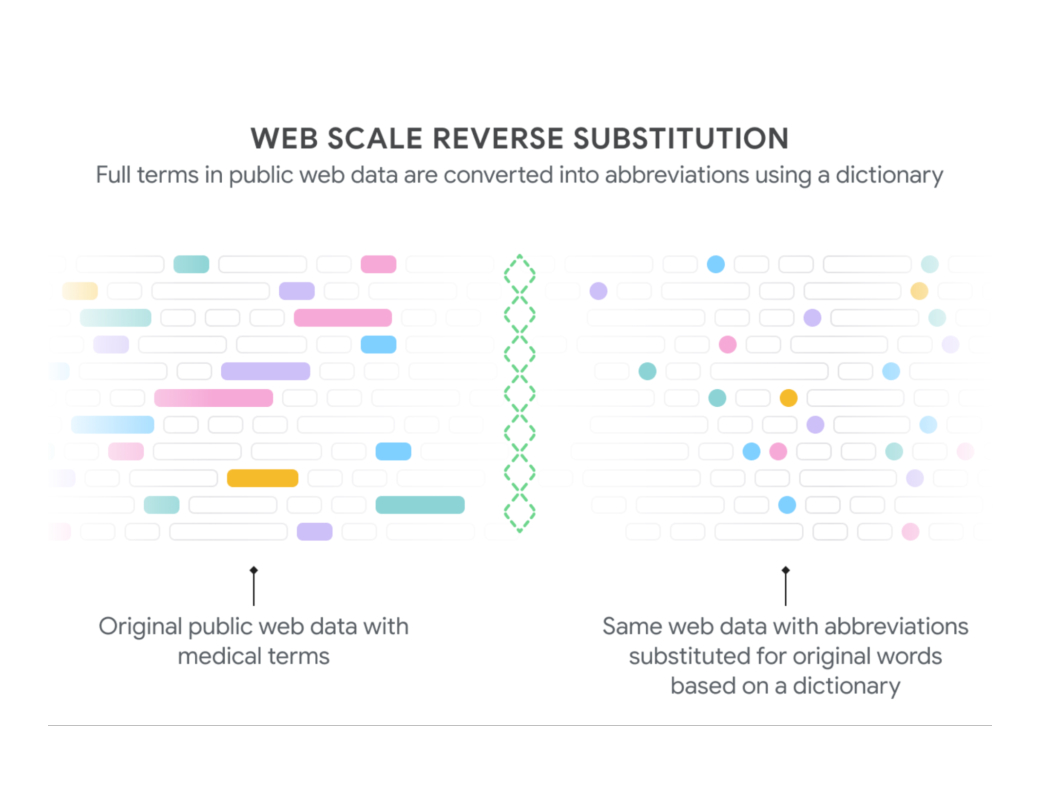
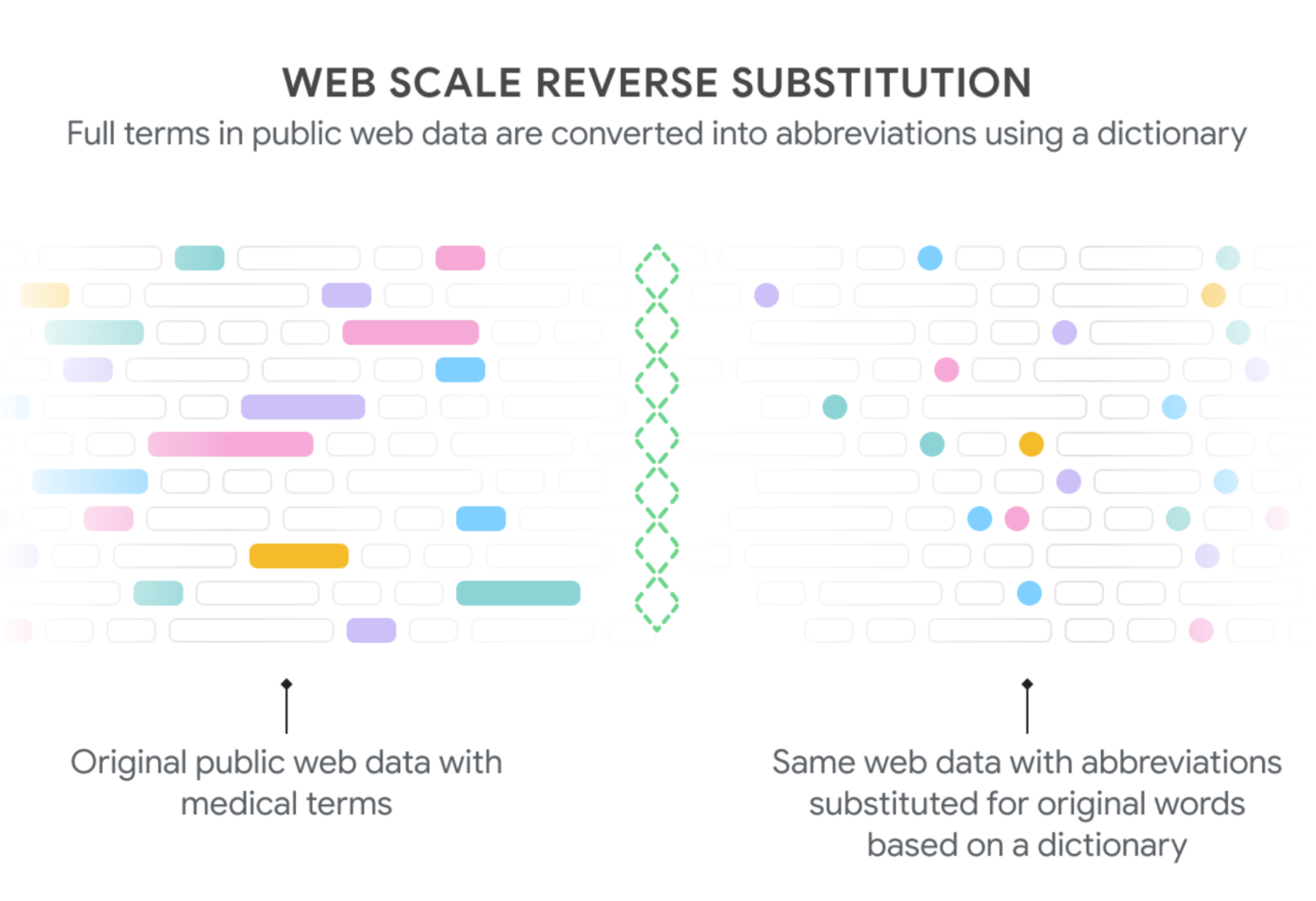 |
| We generate text to train our model on the decoding task by extracting phrases from public web pages that have corresponding medical abbreviations (shaded boxes on the left) and then substituting in the appropriate abbreviations (shaded dots, right). Since some words are found much more frequently than others (“patient” more than “posterior tibialis”, both of which can be abbreviated “pt”), we downsampled common expansions to derive a more balanced dataset across the thousands of abbreviations. By Rajkomar et al used under CC BY 4.0. |
Adapting Protein Alignment Algorithms to Unstructured Clinical Text
Evaluation of these models on the particular task of abbreviation expansion is difficult. Because they produce unstructured text as output, we had to figure out which abbreviations in the input correspond to which expansion in the output. To achieve this, we created a modified version of the Needleman Wunsch algorithm, which was originally designed for divergent sequence alignment in molecular biology, to align the model input and output and extract the corresponding abbreviation-expansion pairs. Using this alignment technique, we were able to evaluate the model’s capacity to detect and expand abbreviations accurately. We evaluated Text-to-Text Transfer Transformer (T5) models of various sizes (ranging from 60 million to over 60 billion parameters) and found that larger models performed translation better than smaller models, with the biggest model achieving the best performance.
Creating New Model Inference Techniques to Coax the Model
However, we did find something unexpected. When we evaluated the performance on multiple external test sets from real clinical notes, we found the models would leave some abbreviations unexpanded, and for larger models, the problem of incomplete expansion was even worse. This is mainly due to the fact that while we substitute expansions on the web for their abbreviations, we have no way of handling the abbreviations that are already present. This means that the abbreviations appear in both the original and rewritten text used as respective labels and input, and the model learns not to expand them.
To address this, we developed a new inference-chaining technique in which the model output is fed again as input to coax the model to make further expansions as long as the model is confident in the expansion. In technical terms, our best-performing technique, which we call elicitive inference, involves examining the outputs from a beam search above a certain log-likelihood threshold. Using elicitive inference, we were able to achieve state-of-the-art capability of expanding abbreviations in multiple external test sets.
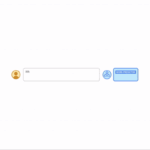
 |
| Real example of the model’s input (left) and output (right). |
Comparative Performance
We also sought to understand how patients and doctors currently perform at deciphering clinical notes, and how our model compared. We found that lay people (people without specific medical training) demonstrated less than 30% comprehension of the abbreviations present in the sample medical texts. When we allowed them to use Google Search, their comprehension increased to nearly 75%, still leaving 1 out of 5 abbreviations indecipherable. Unsurprisingly, medical students and trained physicians performed much better at the task with an accuracy of 90%. We found that our largest model was capable of matching or exceeding experts, with an accuracy of 98%.
How does the model perform so well compared to physicians in this task? There are two important factors in the model’s high comparative performance. Part of the discrepancy is that there were some abbreviations that clinicians did not even attempt to expand (such as “cm” for centimeter), which partly lowered the measured performance. This might seem unimportant, but for non-english speakers, these abbreviations may not be familiar, and so it may be helpful to have them written out. In contrast, our model is designed to comprehensively expand abbreviations. In addition, clinicians are familiar with abbreviations they commonly see in their speciality, but other specialists use shorthand that are not understood by those outside their fields. Our model is trained on thousands of abbreviations across multiple specialities and therefore can decipher a breadth of terms.
Towards Improved Health Literacy
We think there are numerous avenues in which large language models (LLMs) can help advance the health literacy of patients by augmenting the information they see and read. Most LLMs are trained on data that does not look like clinical note data, and the unique distribution of this data makes it challenging to deploy these models in an out-of-the-box fashion. We have demonstrated how to overcome this limitation. Our model also serves to “normalize” clinical note data, facilitating additional capabilities of ML to make the text easier for patients of all educational and health-literacy levels to understand.
Acknowledgements
This work was carried out in collaboration with Yuchen Liu, Jonas Kemp, Benny Li, Ming-Jun Chen, Yi Zhang, Afroz Mohiddin, and Juraj Gottweis. We thank Lisa Williams, Yun Liu, Arelene Chung, and Andrew Dai for many useful conversations and discussions about this work.
[ad_2]
Source link