[ad_1]
Agents cooperate better by communicating and negotiating, and sanctioning broken promises helps keep them honest
Successful communication and cooperation have been crucial for helping societies advance throughout history. The closed environments of board games can serve as a sandbox for modelling and investigating interaction and communication – and we can learn a lot from playing them. In our recent paper, published today in Nature Communications, we show how artificial agents can use communication to better cooperate in the board game Diplomacy, a vibrant domain in artificial intelligence (AI) research, known for its focus on alliance building.
Diplomacy is challenging as it has simple rules but high emergent complexity due to the strong interdependencies between players and its immense action space. To help solve this challenge, we designed negotiation algorithms that allow agents to communicate and agree on joint plans, enabling them to overcome agents lacking this ability.
Cooperation is particularly challenging when we cannot rely on our peers to do what they promise. We use Diplomacy as a sandbox to explore what happens when agents may deviate from their past agreements. Our research illustrates the risks that emerge when complex agents are able to misrepresent their intentions or mislead others regarding their future plans, which leads to another big question: What are the conditions that promote trustworthy communication and teamwork?
We show that the strategy of sanctioning peers who break contracts dramatically reduces the advantages they can gain by abandoning their commitments, thereby fostering more honest communication.
What is Diplomacy and why is it important?
Games such as chess, poker, Go, and many video games have always been fertile ground for AI research. Diplomacy is a seven-player game of negotiation and alliance formation, played on an old map of Europe partitioned into provinces, where each player controls multiple units (rules of Diplomacy). In the standard version of the game, called Press Diplomacy, each turn includes a negotiation phase, after which all players reveal their chosen moves simultaneously.
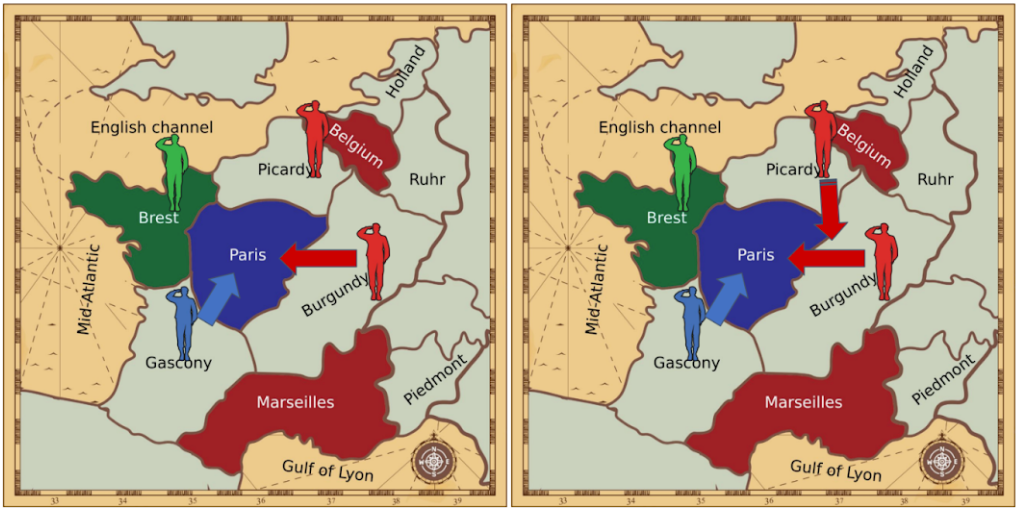
The heart of Diplomacy is the negotiation phase, where players try to agree on their next moves. For example, one unit may support another unit, allowing it to overcome resistance by other units, as illustrated here:

Left: two units (a Red unit in Burgundy and a Blue unit in Gascony) attempt to move into Paris. As the units have equal strength, neither succeeds.
Right: the Red unit in Picardy supports the Red unit in Burgundy, overpowering Blue’s unit and allowing the Red unit into Burgundy.
Computational approaches to Diplomacy have been researched since the 1980s, many of which were explored on a simpler version of the game called No-Press Diplomacy, where strategic communication between players is not allowed. Researchers have also proposed computer-friendly negotiation protocols, sometimes called “Restricted-Press”.
What did we study?
We use Diplomacy as an analog to real-world negotiation, providing methods for AI agents to coordinate their moves. We take our non-communicating Diplomacy agents and augment them to play Diplomacy with communication by giving them a protocol for negotiating contracts for a joint plan of action. We call these augmented agents Baseline Negotiators, and they are bound by their agreements.

Left: a restriction allowing only certain actions to be taken by the Red player (they are not allowed to move from Ruhr to Burgundy, and must move from Piedmont to Marseilles).
Right: A contract between the Red and Green players, which places restrictions on both sides.
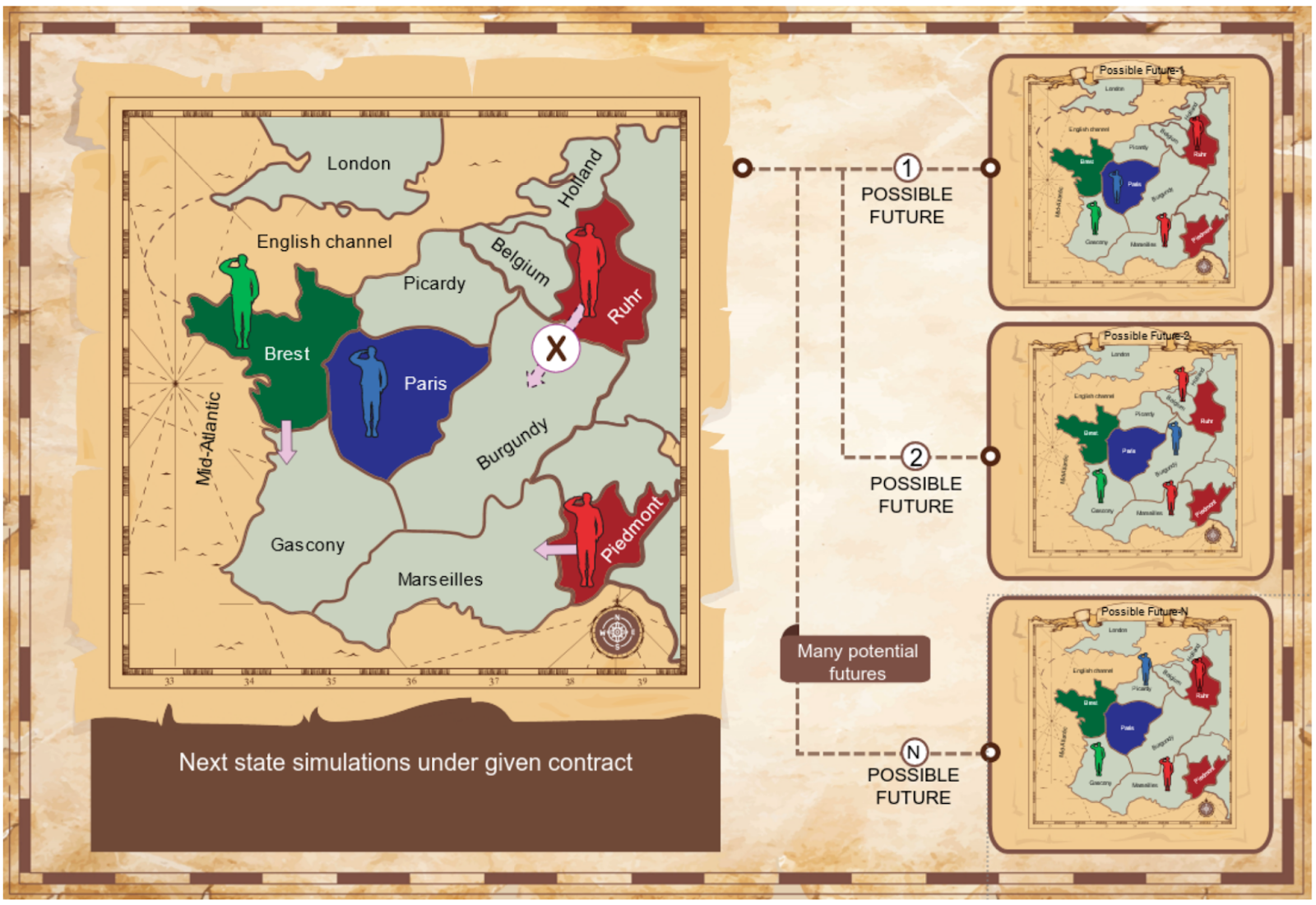
We consider two protocols: the Mutual Proposal Protocol and the Propose-Choose Protocol, discussed in detail in the full paper. Our agents apply algorithms that identify mutually beneficial deals by simulating how the game might unfold under various contracts. We use the Nash Bargaining Solution from game theory as a principled foundation for identifying high-quality agreements. The game may unfold in many ways depending on the actions of players, so our agents use Monte-Carlo simulations to see what might happen in the next turn.
Our experiments show that our negotiation mechanism allows Baseline Negotiators to significantly outperform baseline non-communicating agents.

Agents breaking agreements
In Diplomacy, agreements made during negotiation are not binding (communication is “cheap talk’‘). But what happens when agents who agree to a contract in one turn deviate from it the next? In many real-life settings people agree to act in a certain way, but fail to meet their commitments later on. To enable cooperation between AI agents, or between agents and humans, we must examine the potential pitfall of agents strategically breaking their agreements, and ways to remedy this problem. We used Diplomacy to study how the ability to abandon our commitments erodes trust and cooperation, and identify conditions that foster honest cooperation.
So we consider Deviator Agents, which overcome honest Baseline Negotiators by deviating from agreed contracts. Simple Deviators simply “forget” they agreed to a contract and move however they wish. Conditional Deviators are more sophisticated, and optimise their actions assuming that other players who accepted a contract will act in accordance with it.

We show that Simple and Conditional Deviators significantly outperform Baseline Negotiators, the Conditional Deviators overwhelmingly so.

Encouraging agents to be honest
Next we tackle the deviation problem using Defensive Agents, which respond adversely to deviations. We investigate Binary Negotiators, who simply cut off communications with agents who break an agreement with them. But shunning is a mild reaction, so we also develop Sanctioning Agents, who don’t take betrayal lightly, but instead modify their goals to actively attempt to lower the deviator’s value – an opponent with a grudge! We show that both types of Defensive Agents reduce the advantage of deviation, particularly Sanctioning Agents.

Finally, we introduce Learned Deviators, who adapt and optimise their behaviour against Sanctioning Agents over multiple games, trying to render the above defences less effective. A Learned Deviator will only break a contract when the immediate gains from deviation are high enough and the ability of the other agent to retaliate is low enough. In practice, Learned Deviators occasionally break contracts late in the game, and in doing so achieve a slight advantage over Sanctioning Agents. Nevertheless, such sanctions drive the Learned Deviator to honour more than 99.7% of its contracts.
We also examine possible learning dynamics of sanctioning and deviation: what happens when Sanctioning Agents may also deviate from contracts, and the potential incentive to stop sanctioning when this behaviour is costly. Such issues can gradually erode cooperation, so additional mechanisms such as repeating interaction across multiple games or using a trust and reputation systems may be needed.
Our paper leaves many questions open for future research: Is it possible to design more sophisticated protocols to encourage even more honest behaviour? How could one handle combining communication techniques and imperfect information? Finally, what other mechanisms could deter the breaking of agreements? Building fair, transparent and trustworthy AI systems is an extremely important topic, and it is a key part of DeepMind’s mission. Studying these questions in sandboxes like Diplomacy helps us to better understand tensions between cooperation and competition that might exist in the real world. Ultimately, we believe tackling these challenges allows us to better understand how to develop AI systems in line with society’s values and priorities.
Read our full paper here.
[ad_2]
Source link








