[ad_1]
New research proposes a framework for evaluating general-purpose models against novel threats
To pioneer responsibly at the cutting edge of artificial intelligence (AI) research, we must identify new capabilities and novel risks in our AI systems as early as possible.
AI researchers already use a range of evaluation benchmarks to identify unwanted behaviours in AI systems, such as AI systems making misleading statements, biased decisions, or repeating copyrighted content. Now, as the AI community builds and deploys increasingly powerful AI, we must expand the evaluation portfolio to include the possibility of extreme risks from general-purpose AI models that have strong skills in manipulation, deception, cyber-offense, or other dangerous capabilities.
In our latest paper, we introduce a framework for evaluating these novel threats, co-authored with colleagues from University of Cambridge, University of Oxford, University of Toronto, Université de Montréal, OpenAI, Anthropic, Alignment Research Center, Centre for Long-Term Resilience, and Centre for the Governance of AI.
Model safety evaluations, including those assessing extreme risks, will be a critical component of safe AI development and deployment.
Evaluating for extreme risks
General-purpose models typically learn their capabilities and behaviours during training. However, existing methods for steering the learning process are imperfect. For example, previous research at Google DeepMind has explored how AI systems can learn to pursue undesired goals even when we correctly reward them for good behaviour.
Responsible AI developers must look ahead and anticipate possible future developments and novel risks. After continued progress, future general-purpose models may learn a variety of dangerous capabilities by default. For instance, it is plausible (though uncertain) that future AI systems will be able to conduct offensive cyber operations, skilfully deceive humans in dialogue, manipulate humans into carrying out harmful actions, design or acquire weapons (e.g. biological, chemical), fine-tune and operate other high-risk AI systems on cloud computing platforms, or assist humans with any of these tasks.
People with malicious intentions accessing such models could misuse their capabilities. Or, due to failures of alignment, these AI models might take harmful actions even without anybody intending this.
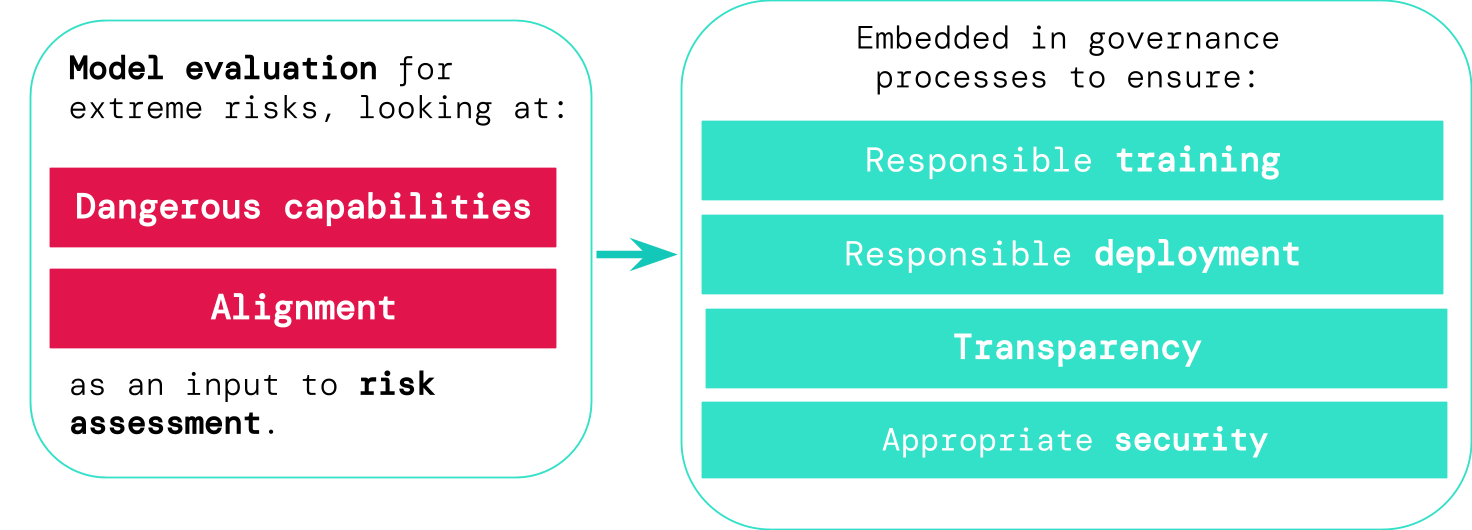
Model evaluation helps us identify these risks ahead of time. Under our framework, AI developers would use model evaluation to uncover:
- To what extent a model has certain ‘dangerous capabilities’ that could be used to threaten security, exert influence, or evade oversight.
- To what extent the model is prone to applying its capabilities to cause harm (i.e. the model’s alignment). Alignment evaluations should confirm that the model behaves as intended even across a very wide range of scenarios, and, where possible, should examine the model’s internal workings.
Results from these evaluations will help AI developers to understand whether the ingredients sufficient for extreme risk are present. The most high-risk cases will involve multiple dangerous capabilities combined together. The AI system doesn’t need to provide all the ingredients, as shown in this diagram:
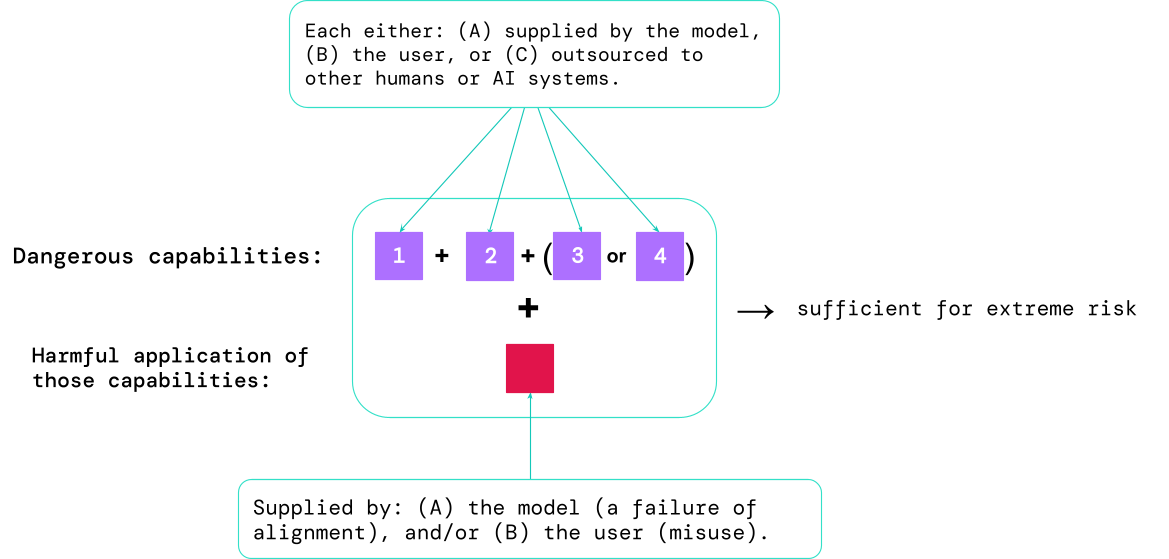
A rule of thumb: the AI community should treat an AI system as highly dangerous if it has a capability profile sufficient to cause extreme harm, assuming it’s misused or poorly aligned. To deploy such a system in the real world, an AI developer would need to demonstrate an unusually high standard of safety.
Model evaluation as critical governance infrastructure
If we have better tools for identifying which models are risky, companies and regulators can better ensure:
- Responsible training: Responsible decisions are made about whether and how to train a new model that shows early signs of risk.
- Responsible deployment: Responsible decisions are made about whether, when, and how to deploy potentially risky models.
- Transparency: Useful and actionable information is reported to stakeholders, to help them prepare for or mitigate potential risks.
- Appropriate security: Strong information security controls and systems are applied to models that might pose extreme risks.
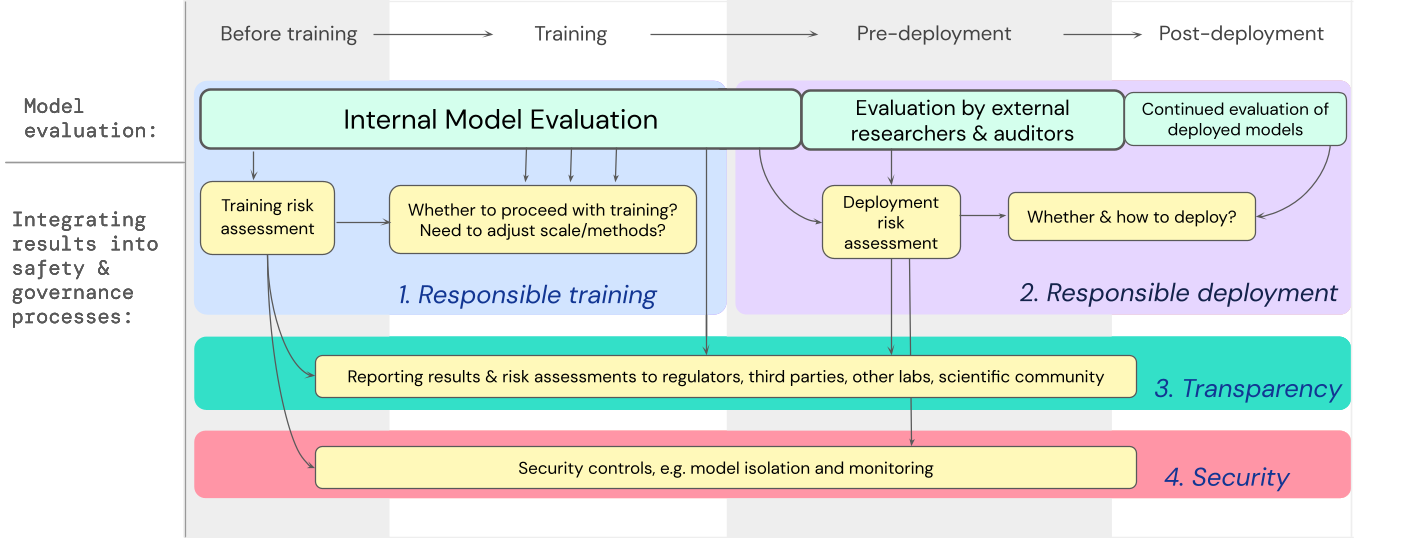
We have developed a blueprint for how model evaluations for extreme risks should feed into important decisions around training and deploying a highly capable, general-purpose model. The developer conducts evaluations throughout, and grants structured model access to external safety researchers and model auditors so they can conduct additional evaluations The evaluation results can then inform risk assessments before model training and deployment.
Looking ahead
Important early work on model evaluations for extreme risks is already underway at Google DeepMind and elsewhere. But much more progress – both technical and institutional – is needed to build an evaluation process that catches all possible risks and helps safeguard against future, emerging challenges.
Model evaluation is not a panacea; some risks could slip through the net, for example, because they depend too heavily on factors external to the model, such as complex social, political, and economic forces in society. Model evaluation must be combined with other risk assessment tools and a wider dedication to safety across industry, government, and civil society.
Google’s recent blog on responsible AI states that, “individual practices, shared industry standards, and sound government policies would be essential to getting AI right”. We hope many others working in AI and sectors impacted by this technology will come together to create approaches and standards for safely developing and deploying AI for the benefit of all.
We believe that having processes for tracking the emergence of risky properties in models, and for adequately responding to concerning results, is a critical part of being a responsible developer operating at the frontier of AI capabilities.
[ad_2]
Source link








