
[ad_1]

Curiosity-driven exploration is the active process of seeking new information to enhance the agent’s understanding of its environment. Suppose that the agent has learned a model of the world that can predict future events given the history of past events. The curiosity-driven agent can then use the prediction mismatch of the world model as the intrinsic reward for directing its exploration policy towards seeking new information. As follows, the agent can then use this new information to enhance the world model itself so it can make better predictions. This iterative process can allow the agent to eventually explore every novelty in the world and use this information to build an accurate world model.
Inspired by the successes of bootstrap your own latent (BYOL) – which has been applied in computer vision, graph representation learning, and representation learning in RL – we propose BYOL-Explore: a conceptually simple yet general, curiosity-driven AI agent for solving hard-exploration tasks. BYOL-Explore learns a representation of the world by predicting its own future representation. Then, it uses the prediction-error at the representation level as an intrinsic reward to train a curiosity-driven policy. Therefore, BYOL-Explore learns a world representation, the world dynamics, and a curiosity-driven exploration policy all-together, simply by optimising the prediction error at the representation level.
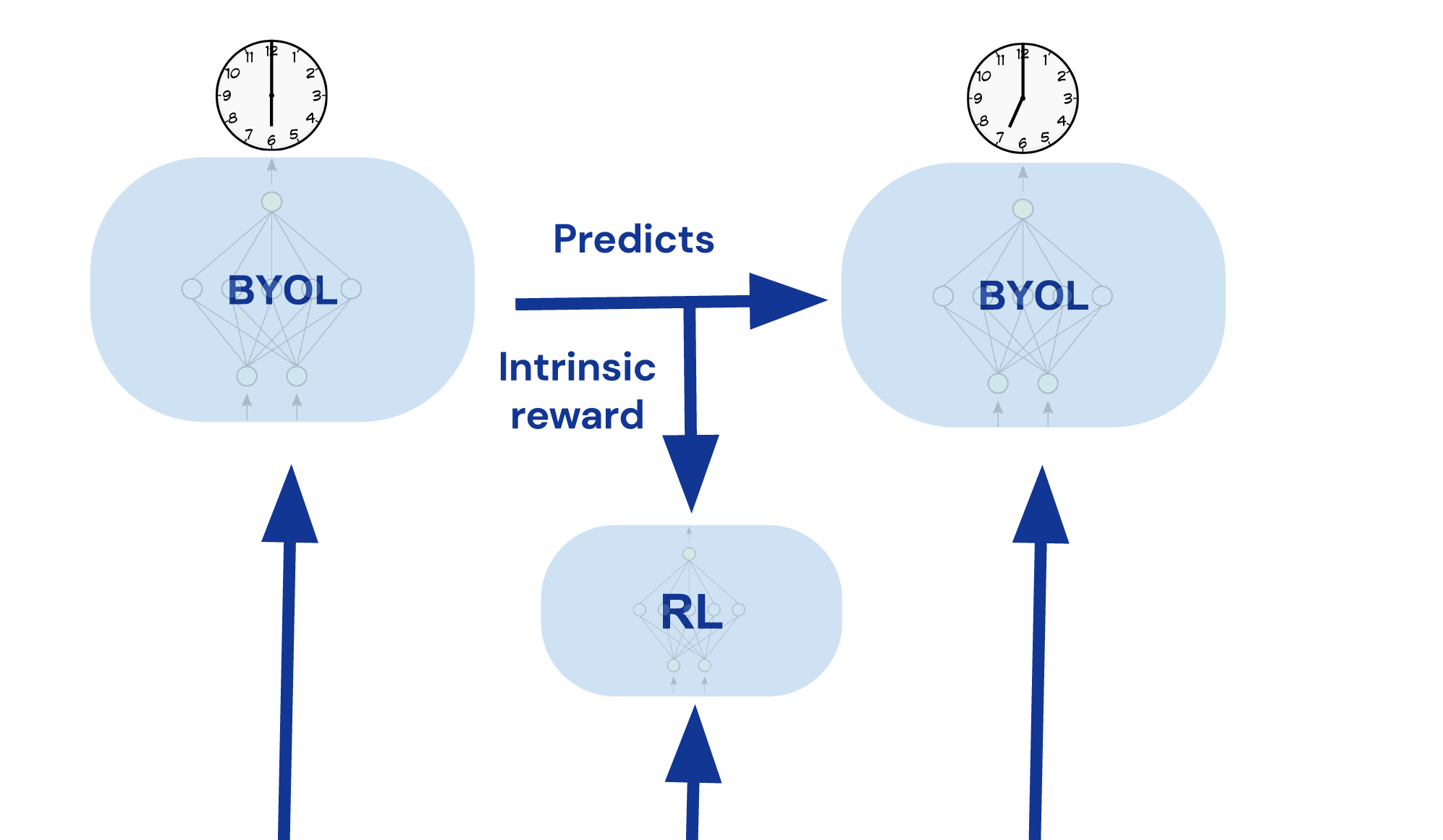

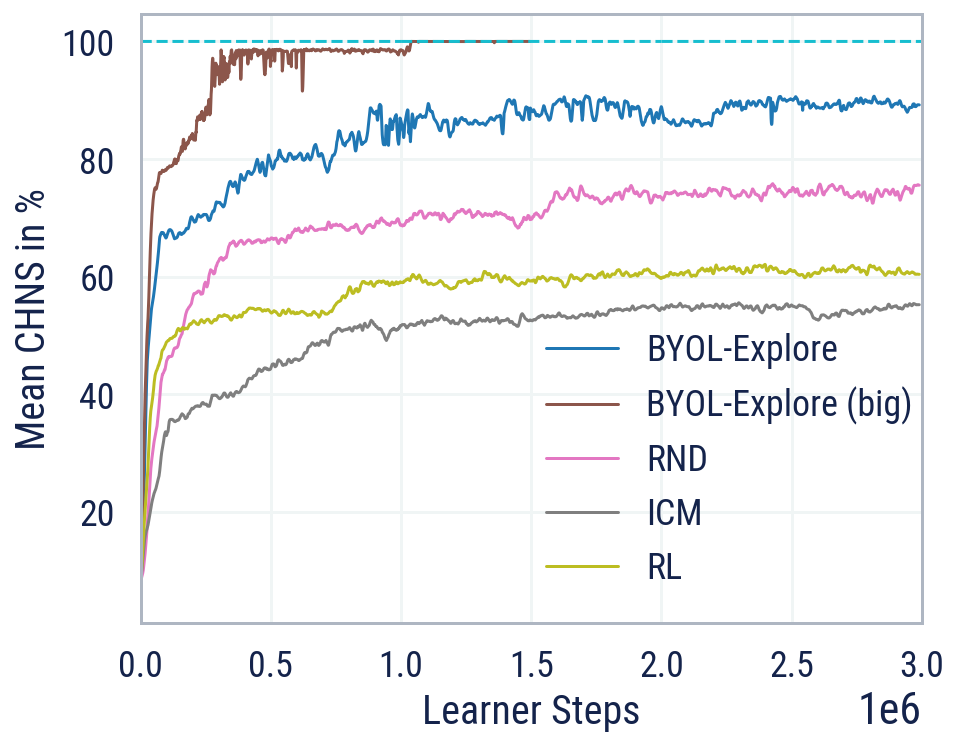
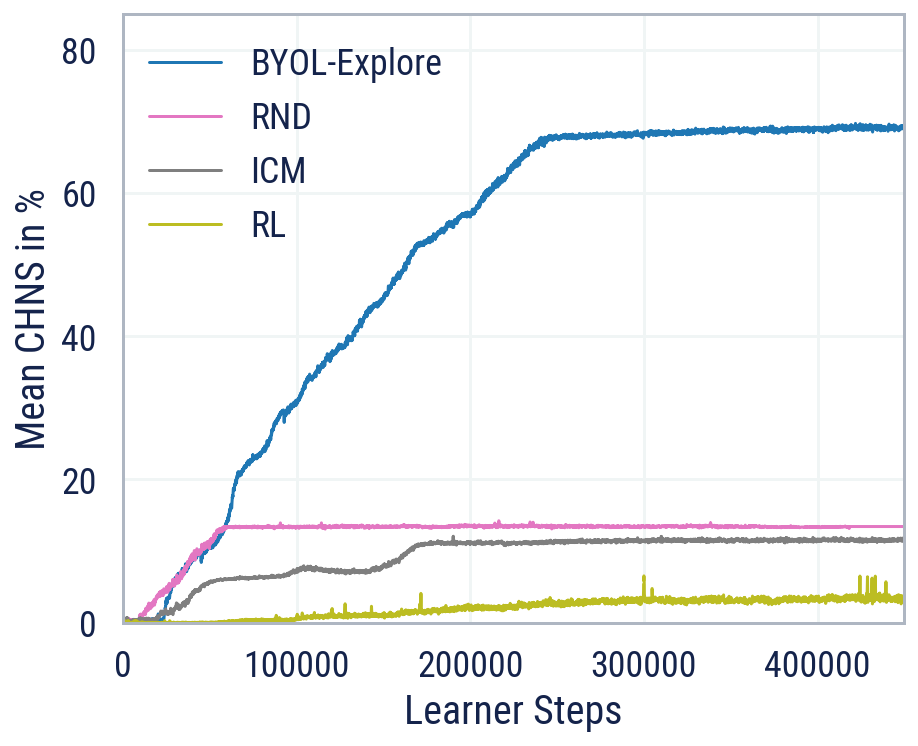
Despite the simplicity of its design, when applied to the DM-HARD-8 suite of challenging 3-D, visually complex, and hard exploration tasks, BYOL-Explore outperforms standard curiosity-driven exploration methods such as Random Network Distillation (RND) and Intrinsic Curiosity Module (ICM), in terms of mean capped human-normalised score (CHNS), measured across all tasks. Remarkably, BYOL-Explore achieved this performance using only a single network concurrently trained across all tasks, whereas prior work was restricted to the single-task setting and could only make meaningful progress on these tasks when provided with human expert demonstrations.
As further evidence of its generality, BYOL-Explore achieves super-human performance in the ten hardest exploration Atari games, while having a simpler design than other competitive agents, such as Agent57 and Go-Explore.
Moving forward, we can generalise BYOL-Explore to highly stochastic environments by learning a probabilistic world model that could be used to generate trajectories of the future events. This could allow the agent to model the possible stochasticity of the environment, avoid stochastic traps, and plan for exploration.
[ad_2]
Source link








